Integrating RCM into a modern SaaS platform may look simple on paper. However, engineers quickly run into endless quirks of payers, clearinghouses, EHRs, clinical workflows, privacy rules, and data standards. The result is brittle integrations and revenue leakage that undermine your product’s growth.
A successful RCM integration is impossible without a sound strategy and architecture. Each phase sets up the next, allowing the team to avoid scope creep and costly reworks. Here’s how to integrate RCM functionality into a healthcare product in a way that is scalable, compliant, and matches how payers actually operate.
Table of contents:
- #1 Lay the groundwork for RCM integration
- #2 Build the technical foundation for RCM workflows
- #3 Integrate RCM functionality
- 3.1 Real-time eligibility
- 3.2 Prior authentication orchestration
- 3.3 Claims & ERA
- 3.4 Denial management workflows
- 3.5 Patient estimates, statements, and payments
- #4 Flesh out reporting & compliance metrics
- #5 Run validation and performance tests
- #6 Roll out in phases, starting with limited customers
#1 Lay the groundwork for RCM integration
Knowing what you need is half the battle. For some companies, visibility into claims is enough; others want to own the entire RCM process. These early choices shape your architectural decisions, clearinghouse needs, and SLAs. Starting with the scope definition prevents costly redesigns and regrets later on.
1.1 Define the RCM capabilities your product truly needs
The ideal scope depends on the customers you target, their payer mix, and your existing billing processes. Practice size and specialty requirements are just as important.
While serving dieticians, for example, you have to deal with fewer CPT codes but most of the customers are yet to go in-network. With behavioral health professionals, on the other hand, you’re beholden to CFR Part 2 and have to work with a handful of specialized payers (Optum Behavioral Health, Magellan, and Beacon Health), each having their specific rules.
Companies that do not yet have a clear RCM integration scope would benefit immensely from a short discovery phase. At MindK, it’s usually based around three key tasks:
- Exposing real billing burdens of your target users, such as high denial rates, manual eligibility checks, lack of visibility into claim status, or inconsistent payment posting.
- Mapping each pain point to a specific workflow.
- Determining whether to partially support the workflow, fully own it, or avoid it altogether.
With problem-workflow mappings, it’s useful to define both the minimum viable RCM for your product and the maximum RCM depth you are willing to support:
| Read-only depth | Transactional depth | Full orchestration |
| Surfacing payer or billing data without modifying it (e.g., displaying claim status). | Initiating and exchanging data with payers (i.e., submitting claims). | Adds automation, routing, validation, and end-to-end management of the workflow. |
| Sample use case: most customers outsource billing; your product does not yet support structured encounters/coding. | Sample use case: customers expect to manage billing inside the platform; you already capture structured clinical and coverage data. | Sample use case: your core differentiator. |
These early choices determine your clearinghouse strategy, payer integration roadmap, service boundaries, and required staffing.
#1.2 Understand your RCM integration readiness and technical constraints
At this stage, we need to evaluate data completeness, workflow maturity, and existing integrations.
- Do you have all the data elements required for the desired RCM depth? These elements may include demographics, coverage, encounters, diagnoses, procedures, rendering/billing provider details, documentation, and payment information. Map the elements your system already captures, the ones that exist but are inconsistent, and the ones that are missing entirely.
- How structured are the product’s workflows? RCM automation becomes unreliable if providers can chart freely without structured diagnoses, or if charge capture is optional or inconsistent.
- Do you have any existing integrations with EHRs, PMSs, or clearinghouses? Are there mechanisms in place to handle high-volume, stateful, asynchronous data exchange? How much payer variability is the team prepared to support?
Answering these questions prevents accidental over-commitment and informs the feasibility of integration. The result is a detailed assessment that prioritizes blockers, dependencies, and prerequisites to address before RCM integration.
1.3 Map regulatory and interoperability requirements
These requirements shape the technical boundaries for RCM workflows. To avoid costly reworks, we recommend framing this phase around three questions:
- What data do we need to exchange?
- Who are we exchanging it with?
- How must that exchange be governed?
Regulatory standards like USCDI v3 and X12 define the data that must be captured, and how consistently it must be represented.
Instead of checking whether you “support FHIR,” map exactly which FHIR resources (Coverage, Claim, Prior Authorization, ExplanationOfBenefit, Patient, Practitioner) are relevant to your chosen RCM workflows and what data your product must supply or consume for each. This reveals whether your domain model and APIs are adequate without a redesign.
Next, identify your integration counterparties. Connecting with clearinghouses involves different expectations than payer FHIR APIs or provider-facing systems. Each integration target imposes constraints like payload structure, rate limits, response variability, and documentation quality.
Finally, examine governance requirements (as outlined in our guide on the latest changes to RCM regulations). HIPAA and 42 CFR Part 2 drive consent and redisclosure controls. CMS-0057-F pushes payers toward FHIR-based prior authorization and claims data exchange.
These rules determine not just what you build but how you enforce access, track disclosures, and log activity.
1.4 Define a consistent RCM domain model and terminology
Our next goal is to create a unified vocabulary and structure to remain predictable, even when payers behave inconsistently.
Start by defining canonical entities: Patient, Coverage, Encounter, Charge, Claim, Prior Authorization, Payment, Adjustment, Denial. For each, specify required attributes, their provenance (who supplies them), and the lifecycle events that modify them. This makes every downstream action traceable and auditable.
Different payers use different codes, denial categories, attachment rules, and prior auth requirements. Rather than modeling them directly into your product, we’ll need a translation layer that maps payer variability to your canonical model. This way, fragile payer-specific logic doesn’t leak into your core services.
Decide what counts as a claim submission, what triggers a status update, what constitutes a denial vs. a rejection, and how prior auth completion maps to downstream processes. Defining event semantics early allows each service to react consistently to state transitions and simplifies debugging.
#2 Build the technical foundation for RCM workflows
Now, let’s create an architecture capable of handling the myriad of differences between payers, their long-running processes, inevitable delays and failures at every step.
2.1 Design an architecture that supports real-world workflows
Building an integration layer early is usually a good investment. In US healthcare, a provider may interact with hundreds of payers, each with its own protocols, schemas, quirks, and rate limits. Scaling this without a dedicated integration capability becomes chaotic.
One approach to such a layer is a highly decentralized model: dozens of microservices, each encapsulating a specific payer or integration channel. They all have a shared communication layer for protocol-specific concerns like EDI parsing, HTTP client behavior, authentication, retries, and rate limiting. This model is complex but good for scaling and failure isolation.
The other extreme is a centralized integration service or event hub that handles all payer interactions. It is faster to build and simplifies cross-payer observability. As the number of payers and variations grows, the centralized model can become a bottleneck that’s prone to accidental coupling.
Whatever model you choose, certain requirements remain the same. Each integration must be versioned and independently upgradeable. The system should detect API or contract changes immediately through strong observability. Failures in one payer integration must be fully isolated so they do not cascade across the integration layer.
To support observability and recovery, every workflow must emit structured events that allow the reconstruction of timelines. Build dead-letter queues, circuit breakers, distributed tracing (AWS X-Ray, OpenTelemetry), and retry/backoffs into the architecture rather than layering them on later.
2.2 Choose what to build vs. outsource
It makes no sense to reinvent the wheel unless it can become a key differentiator for your platform. Ultimately, the decision depends on three parameters:
- Strategic value of features like intelligent claim scrubbing, denials analytics, or automated prior auth orchestration can be worthwhile. In contrast, raw X12 parsing, clearinghouse connectivity, or payer-specific rule engines provide no such advantage.
- Technical complexity of some components is too high compared to their value. Outsourcing such features as EDI compliance, envelope management, batching, ERA normalization, and attachment handling reduces risk and accelerates time to market.
- Cost of owning payer-specific quirks, SLA expectations, support escalations, and regulatory drift. If a component requires constant maintenance, outsourcing may be more sustainable unless it is central to your differentiation.
Most vendors will end up with a hybrid approach that looks like our example for the behavioral health niche:
| Component | Buy or build? | Vendors | |
| Charge capture & coding UX | Build (high differentiation with specialty workflows; close to clinical UX). | – | |
| Claim scrubbing | Build for specialty logic; outsource base edits. | Waystar, Availity, Change Healthcare (edits libraries) | |
| Eligibility (270/271) connectivity | Outsource (high variability, heavy EDI overhead, payer quirks, uptime burden). | Eligible, Waystar, Availity | |
| Prior auth orchestration | Hybrid (submission transport is a commodity; orchestration, tracking, and automation aren’t). | Cohere Health, Availity (Auth APIs) | |
| Claims (837) submission & routing | Outsource (non-differentiating and costly to maintain). | Waystar, Availity, Office Ally | |
| ERA (835) normalization & auto-posting | Outsource (high complexity with duplicates, reversals, posting order; risky to build from scratch). | Waystar, Availity, Change Healthcare | |
| Denials categorization | Build (behavioral health has unique denial patterns, such as authorization lapses, session caps, credentialing. Strong differentiator). | – | |
| Patient estimates & statements | Build (tied to UX, transparency, and your product’s financial experience layer). | – | |
| Payment processing | Outsource (commodity, highly regulated, and requires compliance). | Stripe Health, InstaMed, Rectangle Health | |
| Payer rules engine | Outsource, unless highly specialized (hard to maintain, constant change, high operational overhead). | Alaffia, Optum Payer Connectivity, Availity | |
| Analytics & reporting | Build (core differentiator). | – | |
2.3 Identity, tenancy, and consent foundations
These foundations determine whether your RCM functionality is safe, auditable, and scalable.
Every action must be tied to a user, organization, role, and purpose. For example, reading claim data is different from modifying a PA request or posting a payment. A flexible, explicit authorization model avoids over-permissioning and reduces risk.
It’s recommended to design tenancy around your data-access patterns. Decide whether you will use pooled or isolated storage. Understand how multi-location groups, MSOs, and outsourced billers fit into your model. Avoid simplistic tenant boundaries that break when organizations share billing teams.
For the purpose of auditing and automated enforcement, consent should be treated as a data object with:
- Well-defined scope (category, purpose, permitted recipients, geo limits, and duration).
- Provenance (who captured the data, when, and how).
- Revocation lifecycle.
These foundations ensure downstream workflows inherit correct access controls without requiring service-specific patches.
2.4 Core observability & audit logging
This is what provides definitive answers as to what went wrong, why, and how to fix it. Early implementation allows you to scale integrations and troubleshoot payer behavior without destabilizing the product.
A common assumption that it’s better to log more rather than less doesn’t work in healthcare RCM. Regulations prohibit logging personal information, such as emails and names, even if the logging system is encrypted. It’s recommended to log only key values that help you identify the entities by using internal data
At the architectural level, observability requires workflow-level events, integration diagnostics, and user-facing insights. For reliable analytics, each state transition should emit structured, consistent events (eligibility request received, claim queued, prior auth submitted, attachment requested, ERA applied, denial categorized).
Integration diagnostics is another important component. It requires capturing request IDs, correlation keys, retries, backoff attempts, error categories, and response payloads to make payer debugging tractable.
#3 Integrate the RCM functionality
Depending on the requirements, you might need eligibility verification, prior auth, claims, denials, and patient pay functionality. Each has its own data requirements, external dependencies, timing constraints, and user-facing expectations.
Each module has its own challenges, yet the root cause is the same: RCM integrations are not transactional. They depend on processes that span multiple external systems, take days or weeks to complete, and do not always produce predictable results.
Your system must behave predictably, even though payers and clearinghouses absolutely do not. Here’s how to solve this challenge with each RCM integration.
3.1 Real-time eligibility
This is your first opportunity to prevent downstream denials. The module must send 270 requests, parse 271 responses, normalize inconsistent payer benefits, expose actionable coverage details, and integrate seamlessly into scheduling and intake. In practice, the integration requires:
- Structured coverage capture (subscriber, patient relationship, group number, plan type, and benefit accumulators).
- A normalization layer to convert payer-specific 271 formats into consistent benefit categories (deductible, copay, coinsurance, OON rules).
- Integration with scheduling and intake workflows so staff can verify benefits before the visit, not during or after.
- Automated re-checking for recurring appointments, high-risk plans, or soon-to-expire coverage.
One of the main challenges in eligibility verification is that each insurer has specific rules. Clearinghouses like Stedi do not always return all the necessary information, which might increase denials.
It’s often necessary to enrich this data with information from multi-payer portals (Availity, American Specialty Health, UnitedHealthcare). This second verification layer is also a challenge, as these portals seldom expose a standardized API. MindK is currently adding a third verification level in our specialty-agnostic eligibility tool.
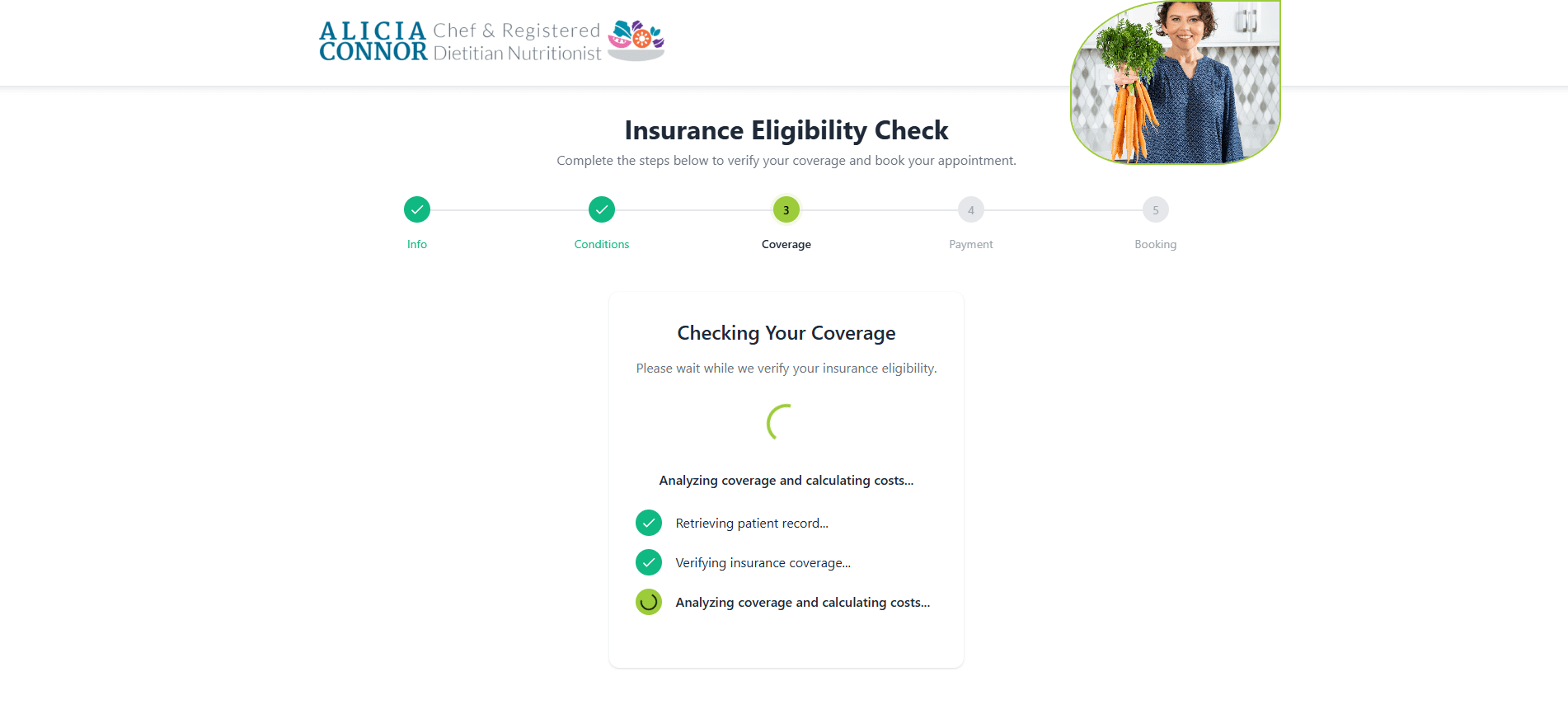
Comprehensive eligibility checking tool developed by MindK
3.2 Prior auth orchestration
Prior authorization (PA) is the highest-risk module in any RCM integration.
It is a long-running, multistep workflow that hinges on external systems or inconsistent manual processes. A reliable PA integration requires a fault-tolerant orchestration engine rather than a simple request/response pipeline:
- State machine with an orchestration engine that allows long-running executions to be traceable and auditable (e.g., Step Functions as a saga coordinator).
- Explicit lifecycle model (Draft → Submitted → Info Requested → In Review → Approved/Denied → Expiring).
- Transition between states based on events, such as payer responses, timeouts, or a manual user escalation. Using EventBridge/SNS + SQS to publish and consume integration events allows you to rebuild state regardless of external volatility.
- Idempotence and replayability to handle delayed, duplicated, or out-of-order events. The state machine, for instance, should ignore duplicate events, hold until dependencies are resolved, and compensate if a previous state needs reversal.
- Durable state storage to track the current state of each authorization request and transaction history (DynamoDB or Aurora with a schema that records currentState, lastTransitionEvent, context data, and history log). This way, you can reconstruct workflows, even if parts of the system go down or external payers misbehave.
- Transport abstraction layer that can support multiple submission channels for payers (X12 278, FHIR PAS, portals, manual processes). Avoid hard-coding payer logic into the core workflow service
- Versioned S3 document storage. Payers often request attachments, such as clinical notes, treatment plans, and assessments. With a separate manifest per PA request, the team will always know which files were submitted when.
- Robust follow-up automation. PA workflows routinely stall due to missing information, delayed responses, or portal-only updates. Scheduled background jobs can re-poll payers at safe intervals, detect prolonged inactivity, escalate to users when manual action is required, and renew expiring authorizations before deadlines.
- Logging of every interaction for auditability by integrating with CloudWatch Logs, X-Ray, or Datadog. Emit structured events for each submission, response, request for information, attachment upload, and expiration.
A well-implemented orchestration engine reduces avoidable denials and eliminates one of the largest sources of provider frustration.
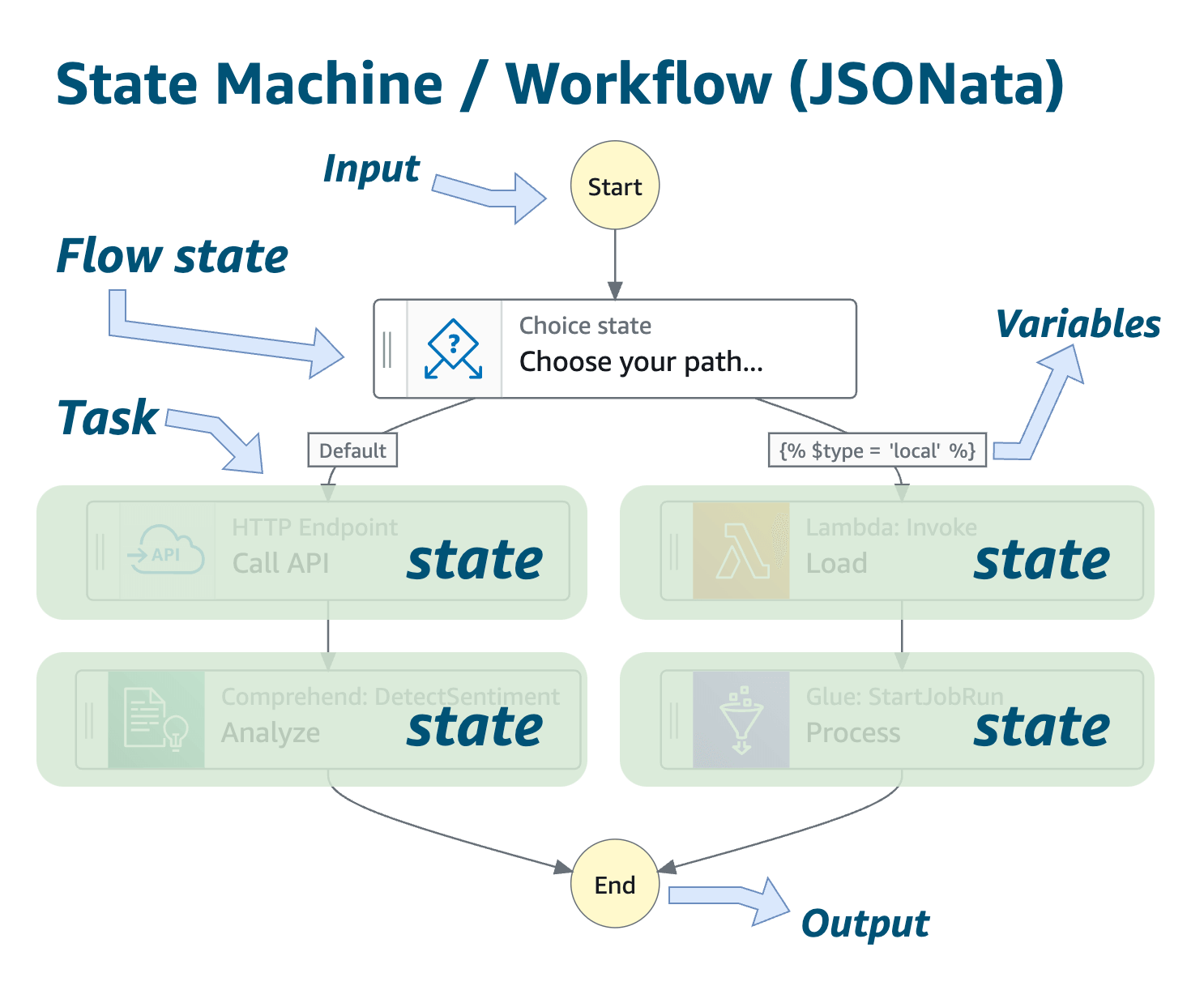
Source: Amazon Web Services
3.3 Claims & ERA
We consider this to be the second most challenging module in RCM integration. Without rigorous normalization, idempotence, and reconciliation patterns, you risk downstream revenue leakage and billing errors.
Strict, canonical claim modeling serves as the foundation for this step. The team needs to split the claim into predictable components: header, service lines, diagnoses, modifiers, provider data, and rendering/billing NPI. Claims should be represented in a payer-agnostic, stable structure. Treat payer-specific quirks as transformations, not as part of your core schema.
Now the team can implement the remaining components of claims & ERA integration:
- Claim creation from encounter data with required NPI, taxonomy, place of service, diagnoses, CPT/HCPCS, modifiers, and charge amounts. The claim generation logic must produce the same claim every time for the same encounter data to prevent reconciliation failure.
- Multi-layer edits engine. A modular rule framework can cover base compliance edits (X12, CCI), payer-specific rules, specialty rules, pre-adjudication checks, and coverage-driven validations.
- Routing to clearinghouses with batching, envelope management, and idempotent replay.
- Status tracking, normalizing payer responses into consistent states (accepted, accepted with errors, rejected, under review).
- ERA ingestion, mapping 835 segments into your canonical model.
- Auto-posting payments and adjustments directly to encounters or ledger.
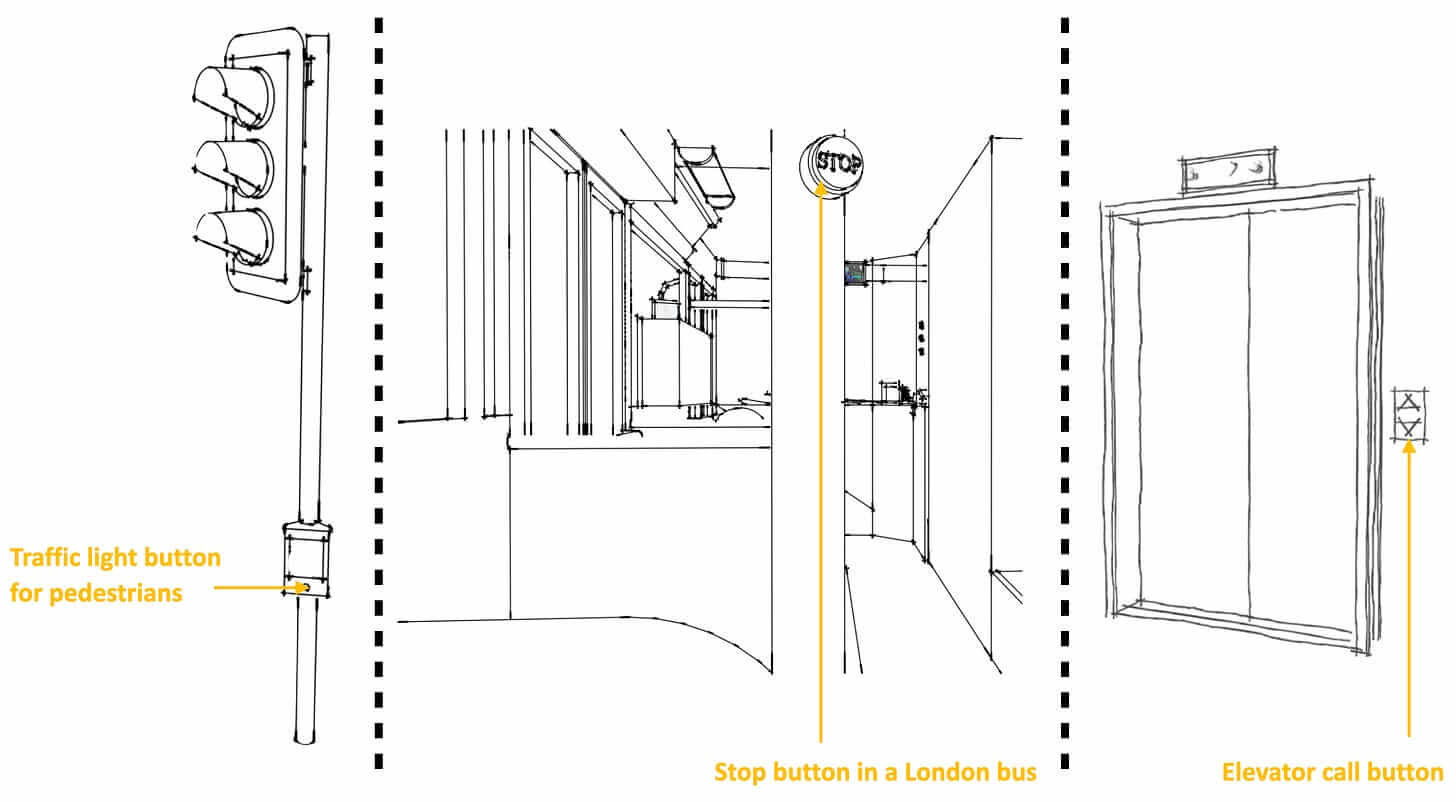
Three examples of idempotency in the real world. The outcome is always the same, no matter how many times you press the elevator button.
Image source: FreeCodingCamp
Since the RCM is directly tied to the money, observability for the business team should be at the top of the list. The system should have dashboards or reports that display the number of claims processed, a list of failed claims, and identify any adverse trends.
It must also have a mechanism to detect ‘stuck’ claims, such as those that haven’t been updated for a week, when the usual processing time is 3 days. So, the system should flag this for both the RCM and the technician team.
Besides technical measures, you’ll also need operational procedures to deal with failures. Let’s say a claim wasn’t created successfully, and the retry has failed a few times. Who should take care of it? How should it be communicated?
As an example, let’s look at our recent project involving EHR and RCM integration. When this kind of operation fails, the application assigns a ticket to the RCM team in the internal system. They review the ticket, and if it looks OK from the business point of view, they redirect it to the technical team.
The Lactation Network, a custom EHR system developed by MindK
3.4 Denial management workflows
Denials are where most RCM products fail, because payers express denial reasons inconsistently. To convert noisy payer messages, we’ll need:
- Denial normalization, mapping payer codes into a consolidated taxonomy (eligibility, medical necessity, coding, authorization, billing error, contractual issues).
- Root-cause classification, connecting denials to upstream failures (missing PA, expired coverage, incorrect diagnosis pairing).
- Work queues for billers, organized by denial type, payer, aging, and financial impact.
- Corrected claim automation, prepopulating corrected claims with the necessary adjustments.
Even though 835 ERAs include formal CARC/RARC codes, payers routinely use generic codes (e.g., CO-97 “benefit not covered”), add free-text remarks with critical detail, bury the real cause in proprietary explanation fields, or send multiple contradictory codes in one ERA line.
As a result, one denial reason may appear as several codes or get buried in unstructured text. Correcting these issues is a prime use case for Machine Learning in healthcare. Using a combination of structured and unstructured fields, we can teach the model to recognize patterns like “CO-197 + this CPT + this text appear = an authorization issue“.
3.5 Patient estimates, statements, and payments
Patient financial engagement is the last part of modern RCM. From the technical point of view, the integration involves a pricing engine, S3 for document generation, third-party payment processors, such as Stripe, and secure audit logs for financial transactions. From the functionality PoV, it needs:
- Cost estimates using eligibility benefits, contracted rates, known allowed amounts, and historical adjudication patterns.
- Digital statements autogenerated from ERAs and plan benefits.
- Mobile-friendly payment flows, integrated with PCI-compliant processors.
- Payment plan logic, particularly relevant in behavioral health where recurring visits are common.
- Reconciliation between patient payments and payer payments, ensuring the ledger is correct.
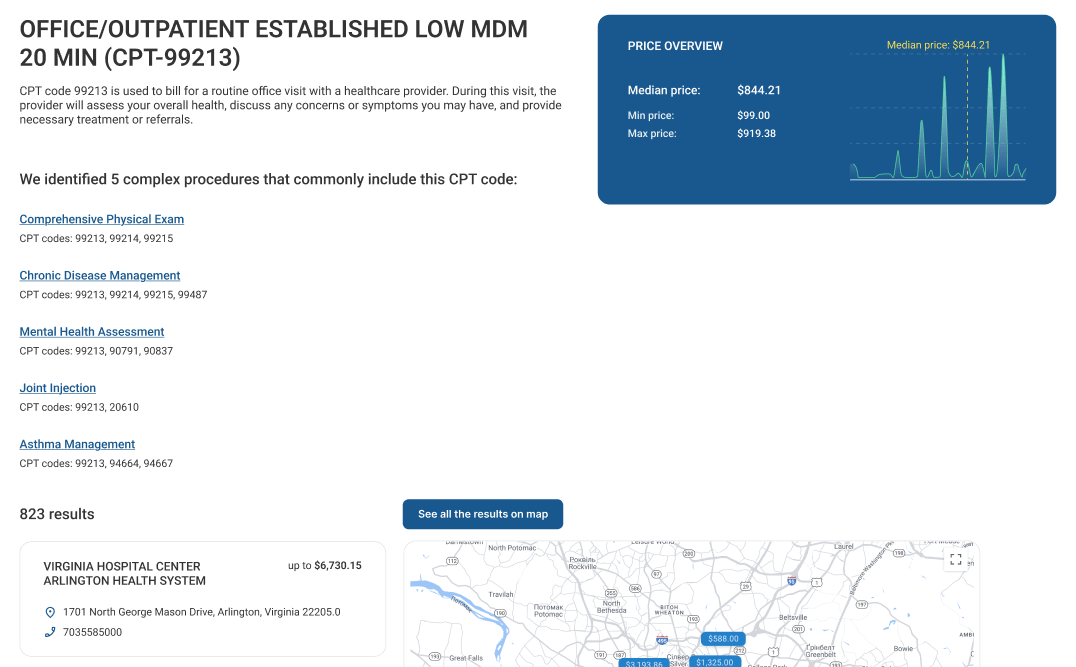
Medical procedure cost estimation in a custom web application developed by MindK
Once core workflows are operating, the next step is transforming raw RCM events into visibility for providers and compliance teams.
#4 Flesh out reporting & compliance metrics
A reporting layer should be genuinely useful, not a collection of charts nobody uses. The backbone for such a layer is formed by the events emitted by workflows at key state transitions:
- Domain events (e.g., claim.created, claim.submitted, pa.requested, era.applied)
- Operational events (retry, timeout, escalation, stale state detection)
- Integration diagnostics (external request/response metadata, correlation IDs, payer latency)
These events should be immutable, timestamped, tenant-scoped, and correlated back to the originating request.
Without time stamps, events can’t become the basis for your RCM analytics and data-driven decisions. If events aren’t tenant-scoped, Tenant A may indirectly access Tenant B’s data by receiving its events. This makes the system vulnerable to data leaks and can disrupt the tenant’s functionality. Correlation IDs allow the team to surface a business transaction from the logs for the purpose of diagnostics. Without correlation IDs, occasional claim creation failures will result in delayed/reduced revenue.
Analytics must normalize payer variability, or reports become unintelligible. A canonical analytical layer should map events into standard measures and dimensions.
| Measures | Dimensions |
| Eligibility success rate | Payer |
| Authorization turnaround time | Rendering provider/location |
| Claim submission throughput, rejections | Visit type/CPT category |
| First-pass acceptance rate | Specialty |
| (Avoidable) denial rates | Encounter date |
| Days in A/R | Plan type |
| Payer-specific adjudication timelines | Denial root cause |
| Patient collection success | |
| Cost-to-collect |
Curated data marts for each of the RCM modules can prevent the pollution of prod workloads. Use a star schema or wide analytical tables, depending on your stack. This is where AWS services like Redshift, Athena, or DynamoDB streams feeding S3-based lakehouses come into play.
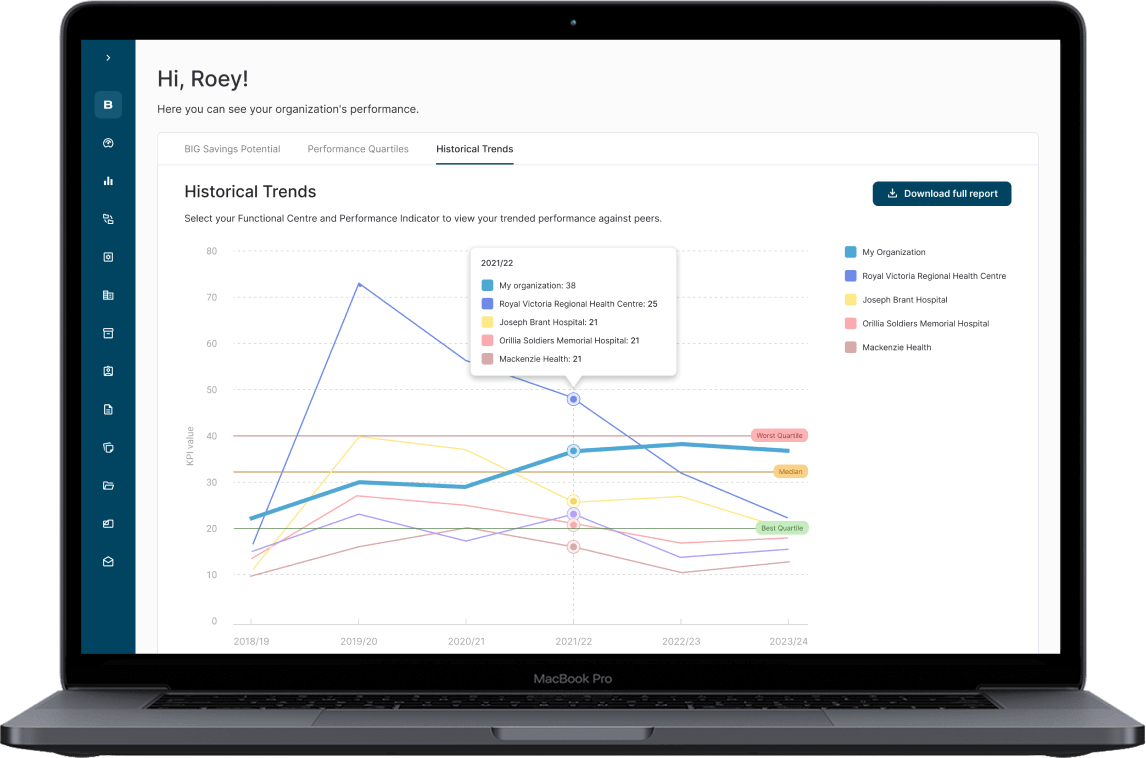
Hospital analytics dashboard in BIG Healthcare that utilizes a Star Schema data warehouse to deal with a growing data volume.
Compliance outputs differ sharply from analytics because they must represent exactly what happened, not aggregated insights. This requires:
- Immutable audit logs showing each change of state with the actor and timestamp.
- End-to-end claim traceability.
- Authorization event logs tied to payer responses and timestamps.
- Access logs that show who viewed PHI, when, and for what purpose.
- Disclosure reports for 42 CFR Part 2 and HIPAA accounting.
- Reproducible “snapshot” reports detailing system state at specific points in time.
Building audit logging once and well saves hundreds of engineering hours over the life of the product. A typical implementation involves S3 with Glacier for immutable logs, EventBridge/Kinesis for event stream storage, DynamoDB streams or Aurora CDC for historical reconstructions, and CloudTrail for access events.
#5 Run validation and performance tests
The team must prove that your system can withstand real-world conditions before it goes live. This means requires several types of API testing under realistic load, failure, and compliance scenarios.
| Test type | Explanation | Tools |
| Load and stress testing | Simulation of realistic and peak loads, increasing concurrency, message backlogs, latency, and payer timeouts. | JMeter |
| Soak testing | Prolonged testing to surface memory leaks, state accumulation, backpressure problems, and queue buildup in long-running workflows. | CloudWatch, Nagios |
| Failure and chaos simulation | Testing with payer/clearinghouse latency, duplicate or out-of-order ERAs, API timeouts, message loss, database failover, DLQ processing. | AWS Fault Injection Service |
| Idempotency testing | Using duplicate or delayed events to validate the system produces a correcteventbridge ledger state. | SQS/EventBridge |
| Compliance, audit readiness | Verifying that state transitions are logged with audit trails, correlation IDs, user/tenant context, and timestamps. | CloudTrail, AWS Config, Vanta |
| Scalability testing | Testing behavior, performance, and data isolation when multiple provider-tenants operate concurrently, share resources, or scale independently. | Kubernetes/ECS |
| Regression testing | Automated testing to detect performance degradation for every new release. | Jenkins/GitHub Actions + JMeter |
#6 Roll out in phases, starting with limited customers
An incremental rollout reduces operational risk. After validating each workflow internally using high-fidelity synthetic data, it’s time to onboard one or two trusted practices in a limited pilot. Choose groups with stable workflows, predictable visit volumes, and staff willing to provide detailed feedback. During this phase, instrument everything:
- Measure eligibility accuracy, track prior-auth turnaround times,
- Observe payer-specific anomalies,
- Monitor ERA ingestion for mismatches or reversals.
Throughout the rollout, use feature flags and tenant-level configuration to control exposure. This decouples deployment from activation and allows the team to pause rollout as soon as anomalies appear.
Conclusion
RCM integration touches clinical data, payer systems, billing workflows, and compliance obligations. With a methodical approach, it makes your platform an essential part of the provider’s financial life.
Although different RCM modules hide different challenges, most of them have a single source. Revenue cycle is a long process that relies on third parties and their quirks. To solve these challenges, MindK implements reliable state machines, explicit lifecycle models with event-based transitions, layers that abstract payer variability, and immutable audit logs. So, do not hesitate to drop us a line if you need technical advice or an experienced team to integrate RCM into your SaaS product.