
We often deal with projects that face a high level of uncertainty. With networking applications, you can’t predict how many connections you’ll have in the future and how complex they’ll get. So it can be hard to pick an optimal tech stack. However, there might be a perfect database for such cases. And this database is called ArangoDB.
As we learned during one of our recent projects, it is fast, flexible, and has a fantastic community. But first, let’s take a look at the requirements we were facing when choosing our tech stack.
The challenge
Some time ago, an early-stage startup contacted our custom software development company to build a new type of social network.
The idea was simple. There are many startups who need funding and there are lots of investors who are interested in the tech sector. But bringing them together isn’t as simple as it sounds.
When searching for a startup that’s worth their money, venture funds have to consider dozens of parameters. And one of the most important factors for any investor is the team composition. Is it well connected? What skills do they have? What networks do they have outside of the company?
These are all essential questions but investors often have no quantitative ways to assess the team besides gut feeling.
And this is where our client’s idea comes into play.
They wanted to develop an app for the visualization of connections within and outside of startup teams. With social network analysis, investors would be able to assess startup teams based on quantitative methods.

Different types of visualization available in the D3 library
The app had a number of requirements that complicated its architecture and made it hard to choose an optimal tech stack:
- All connections for each user had to be visualized as a graph using the D3.js library.
- 2 user types: companies and individuals (with the ability to add universities and other user types in the future).
- A quick and efficient search that would match users with companies and individuals based on their skills and social connections.
- All users should be able to share a part of their profile (i.e. fields in a form) into various networks (i.e. individual entities and field values needed to have different access rights).
- Attributes of all entities in the database needed to be dynamic so that field values could be shared between different social networks.
- The application should be able to recommend different social networks based on connection strength, the data you share in your forms and other attributes.
- The final solution had to include a chat for all user types and a document library with the ability to share files.
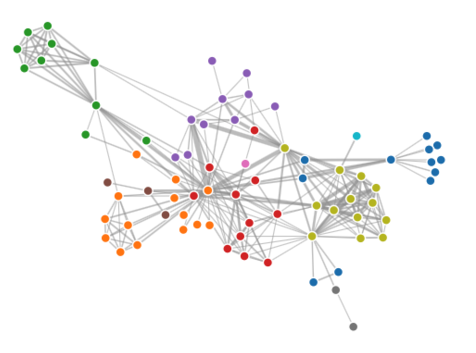
A social network visualized as a graph in the D3 library
Now, choosing a database that would satisfy all of these requirements was quite a challenge.
It’s possible to use dynamic field attributes in a regular SQL database but sharing field values between different social networks is a big problem. Creating additional connecting tables would’ve complicated the application’s architecture and slowed down the queries.
The result would be poor performance.
Now, the need to have different access rights to individual entities like social networks meant creating even more relationships between the database entities. The increased complexity was another reason to look into non-relational databases (also useful for the live chat functionality).
What’s more, our client wanted the app to suggest existing social networks to users based on information in their profiles.
And this is a very hard task for a relational database.
NoSQL vs SQL
As our app was based around social networks and graph visualizations, our choice fell on graph databases where relationships between data are just as important as the data itself.
Database entities are represented as nodes that can have as many attributes as needed. Each node has a direct pointer towards all other related nodes.
These connections between nodes, called relationships, are stored alongside the data.
They must have a starting point, an end node, a direction, and a type. Just like nodes, relationships can have attributes (e.g. weights, strengths, distance, or time intervals).
This network of nodes connected via relationships is known as a graph.
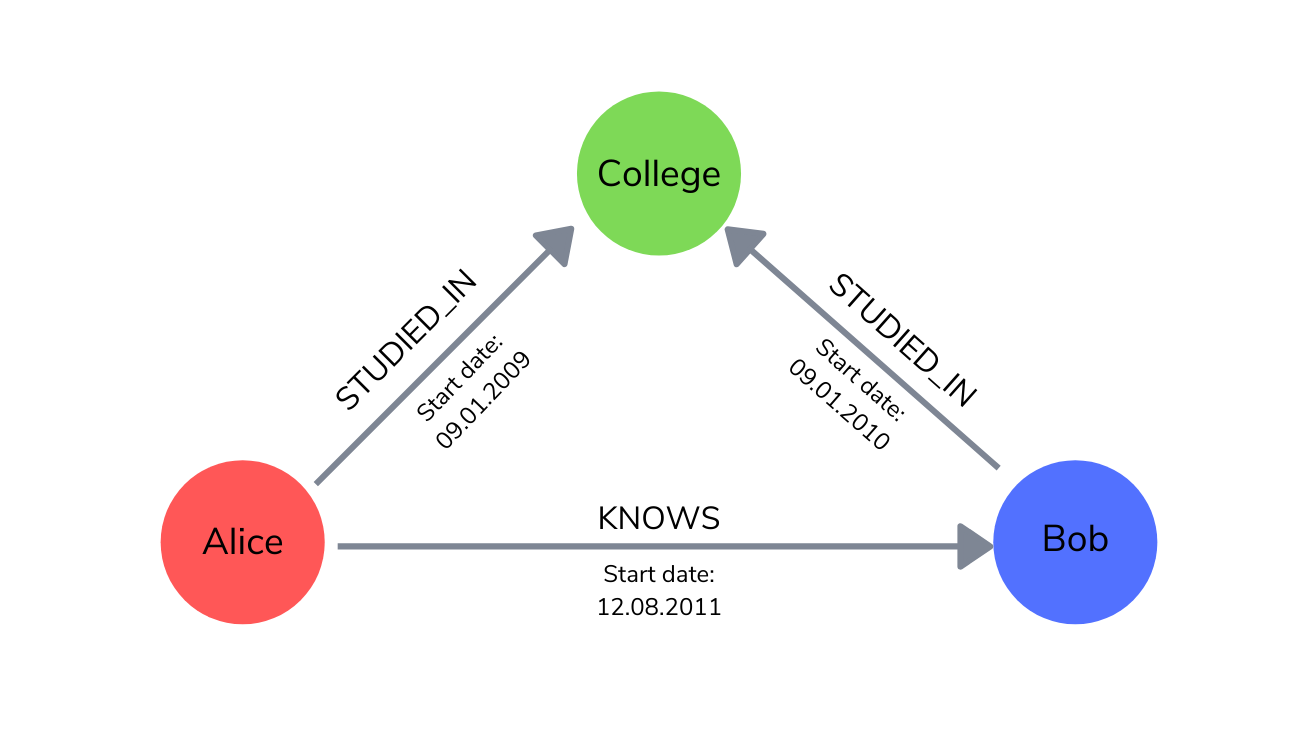
A graph with nodes (circles) and relationships (arrows)
Graph databases shine at complex relationships-intense queries and datasets with many connections. They can search through the neighboring nodes having only a set of starting points and a pattern.
Our initial research pointed us towards Neo4j, one of the leading graph databases.
Its main downside was the high price for use in production. We had to search for another option.
And this option came in the form of ArangoDB, a relatively uncommon database made by German developers.
What is ArangoDB?

Source: G2 ArangoDB reviews
ArangoDB is an open source native multi-model database. It supports graph, document, and key-value data models allowing users to freely combine all data models in a single query.
As applications become increasingly complex, you often need more than one NoSQL database. Using a multi-model database can simplify your architecture by combining several NoSQL types in a single infrastructure.
So, what are the main features that define ArangoDB?
- Easy performance scaling
The database allows you to quickly adapt to increasing requirements for performance and storage with both vertical and horizontal scaling. It also supports the independent scaling of different data models and allows you to quickly scale down your application to save on hardware and operational expenses.
- Consolidation
ArangoDB drastically reduces the number of components to be maintained making your tech stack much less complex.
- Decreased operational complexity
Multi-model databases allow you to use different storage technologies that better fit the way your data is used by different components within your application (i.e. Polyglot Persistence).
- VelocyPack (VPack)
ArangoDB uses binary JSON to store data. It is lean, self-contained, doesn’t allocate too much memory, and covers all of JSON plus dates, binary data, integers, as well as arbitrary precision numbers.
- Powerful fault tolerance system enabled by default
- ArangoDB Query Language (AQL)
ArangoDB allows you to access any data (regardless of its model) using a single declarative query language. It is quite similar to a standard query SQL language with some minor differences:
SELECT * FROM users;//SQLFOR user IN users RETURN user;//AQL<br />SELECT * FROM users WHERE active = 1; //SQLFOR user IN users FILTER user.active == 1 RETURN user;//AQL
As a NoSQL database, ArangoDB features high performance in data storage and retrieval.
But to realize social networks in our application, we needed relations that are absent from typical NoSQL databases.
So we dug into ArangoDB documentation and discovered that it actually supports relations. AQL allows Joining related documents on the fly inside a query without affecting the app’s performance.
Our research showed that ArangoDB could satisfy all our requirements. A single database to cover the whole business logic.
Yet, we had no experience with ArangoDB. The database is comparatively young and has a small community. Moreover, there were very few integrations with frameworks meaning we’d have to write these components by ourselves.
As we analyzed the documentation, we came to the conclusion that all of the ArangoDB cons were canceled out by its pros.
So we took the chance and started the development.

Companies using ArangoDB in their projects
The result
By choosing ArangoDB, we could use a single database for all features: chats, relationships, document sharing, various types of entities (companies, persons, universities, employees, venture funds, etc.).
It can store all connections between nodes and construct graphs that will be constantly updated when you add a new connection.
With ArangoDB, we could easily architect dynamic field attributes. The database allows implementing relations in two ways: by making links to primary keys or via connections and graphs. As we discovered, it’s better to use connections when you have dynamic attributes. And primary keys are better suited for situations when you have a clear understanding of relations between different entities.
What’s more, ArangoDB has an excellent web-interface that allows writing queries and instant viewing of the resulting graphs.
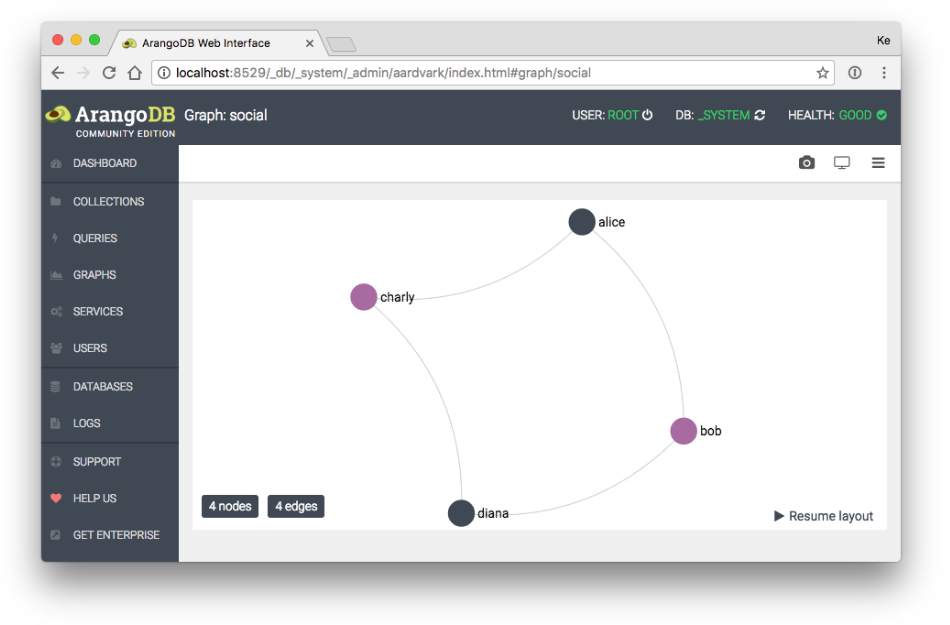
ArangoDB web interface as shown in the documentation
The database supports all the modern deployment options (e.g. Kubernetes, Docker, and clusters for high-load).
It features a flexible and powerful query language (AQL) that covers all the needs of a modern application. The whole graph visualization process is performed with a single query.
Overall, it’s one of the most elegant query languages I’ve ever seen.
ArangoDB fully supports ACID transactions and has excellent performance.
The average search query takes around 0.1 seconds. Even the most complex queries that affect hundreds of social networks take less than half a second. Joining so much data in a relational database would’ve required denormalization or using Elasticsearch with a flat connecting structure to help with the visualization.
We achieved the same thing in ArangoDB without any additional effort.
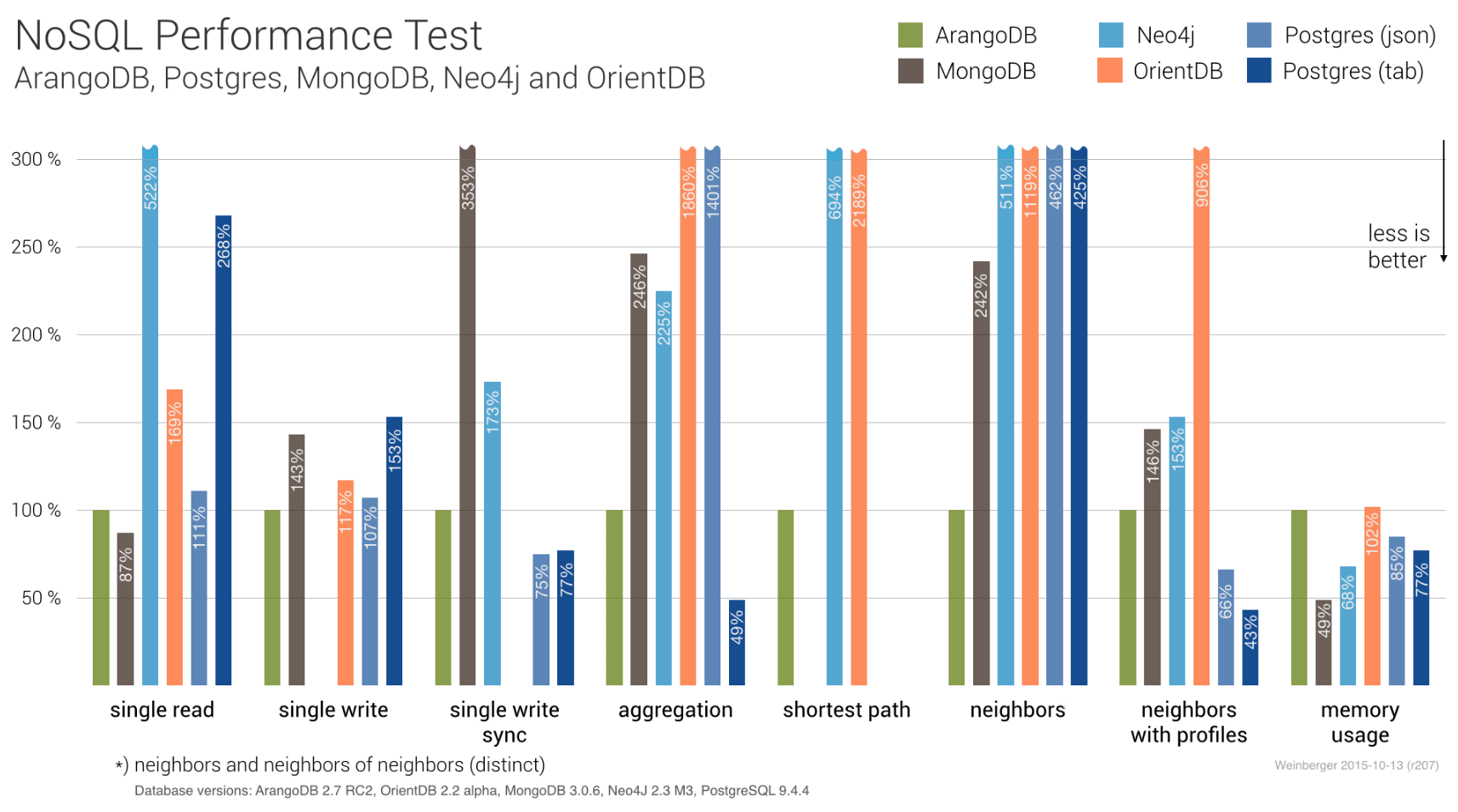
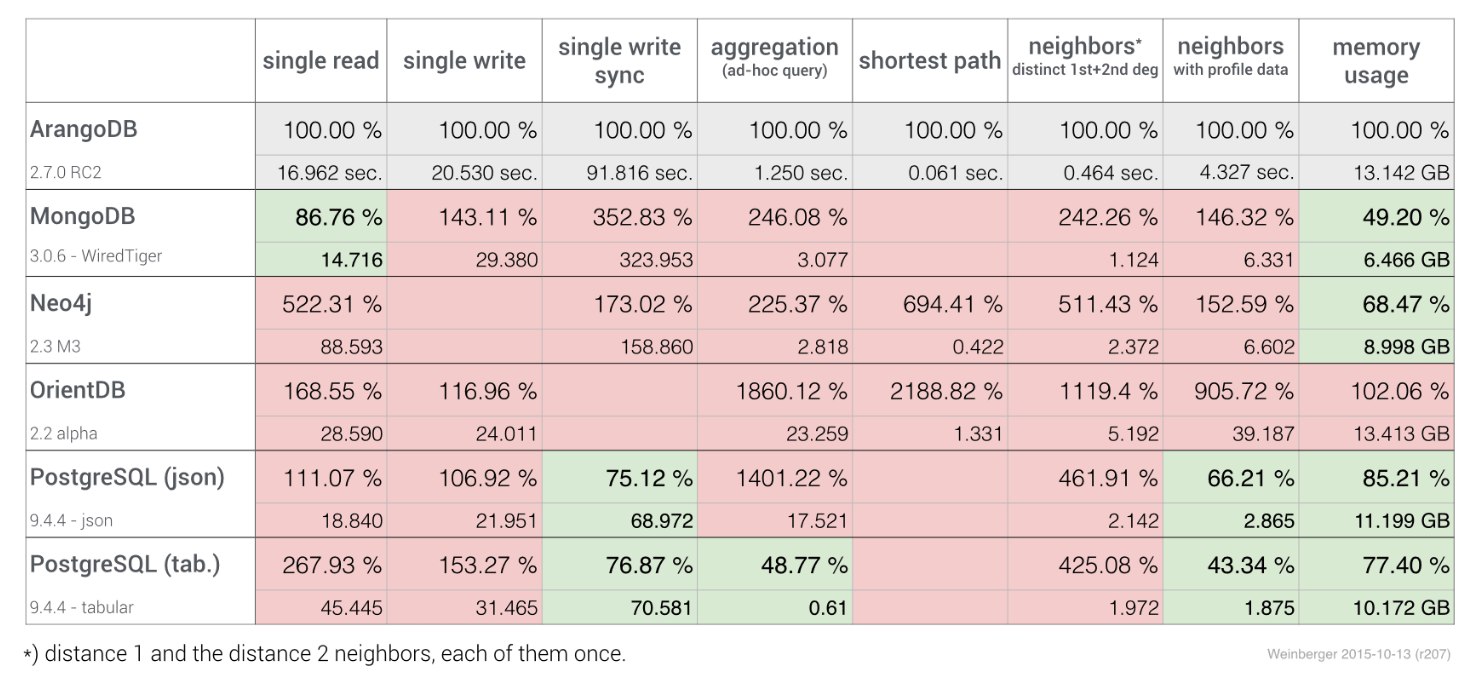
Source: arangodb.com
All our worries about the small community turned out to be unfounded. The database has awesome documentation. It includes over a dozen case studies that highlight success stories of various companies and a cookbook with detailed solutions for various problems.
Moreover, it has a great community in Google groups and an awesome Slack channel.
Once I had an issue with ArangoDB that I couldn’t solve on my own, so I asked a question in the Slack channel. Within 30 minutes I got a detailed answer from one of the database developers.
This is really awesome!
ArangoDB developers constantly organize free webinars that delve into the latest versions of the database which are presented in a very interesting and unusual format.
Conclusions
It was a great pleasure working with ArangoDB.
Of course, there were some difficulties like integrating the database with a framework but, overall, the experiment was a great success and the project was finished on time.
Now, when you choose a database for your project, it’s always worth considering ArangoDB.
If you face a high degree of uncertainty or have complex relations between the entities, ArangoDB might be the database you are looking for.
It has an excellent web interface for managing queries, a powerful query language for managing data, and VelocyPack (VPack) for storage and serialization.
Everything you need in one powerful database.
And if you need help with your next project, you can always contact MindK and schedule a free consultation.




