Single page applications (SPA) are all the rage now. Facebook and Gmail are just a few well-known examples. Everybody familiar with search engine optimization would tell you, SPA SEO is a nightmare. But you shouldn’t discard the tech as useless. Here’s why.
Single page applications are lightning-fast, easy to deploy and provide the butter-smooth user experience. SPAs achieve this by dynamically updating website content without reloading the whole page. Just like in a desktop or native app.
There are a few ways to combine the exceptional speed and user experience of SPA with the discoverability of regular web applications. A number of our projects at MindK follow these ways. Today we’ll share them with you.
Table of contents:
- Why are single page apps bad for SEO?
- How to solve this problem?
- What other steps can you take to optimize your SPA’s discoverability?
- Conclusions.

Why are single page apps bad for SEO?
Traditionally, websites used server-side rendering for their HTML content. This allows search engine bots (called web crawlers or spiders) to index the site’s content. This process (called crawling) is how search engines discover content on your site and make it available to the public.
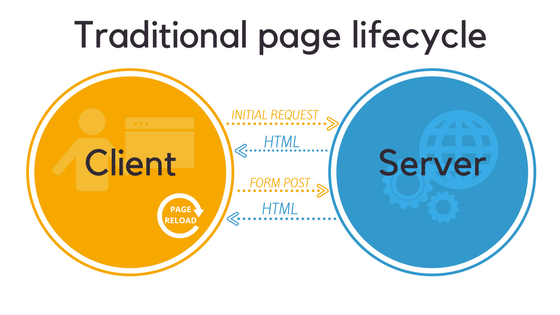
But dynamic content creates issues with server-side rendering. When the tiniest sliver of data on a page changes, the server has to completely re-render it and then send you the new version of the page.
Client-side rendering, on the other hand, allows single page web applications to display dynamic content without reloading the whole page. Your browser receives a bare-bones HTML container and then renders the page’s content using JavaScript.
Now when some part of the content on a page has to be altered, your browser sends an AJAX call to the server. The server in return sends the data (most often in JSON format) your browser requires to update the page.
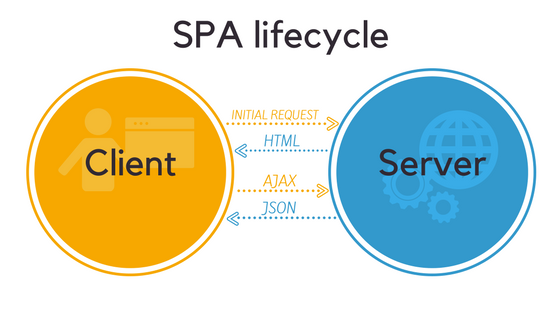
At the same time, client-side rendering is bad for the crawlers. As most of the content is dynamically loaded via JavaScript, spiders have trouble correctly indexing SPA. To them, the content (as seen by a user) is absent from the page.
And without content there’s nothing to show in the search results. Social media bots also have trouble crawling SPA.
This is how your shiny new website/web app becomes an SEO disaster.
How to solve this problem?
1. Avoid Google’s AJAX crawling scheme
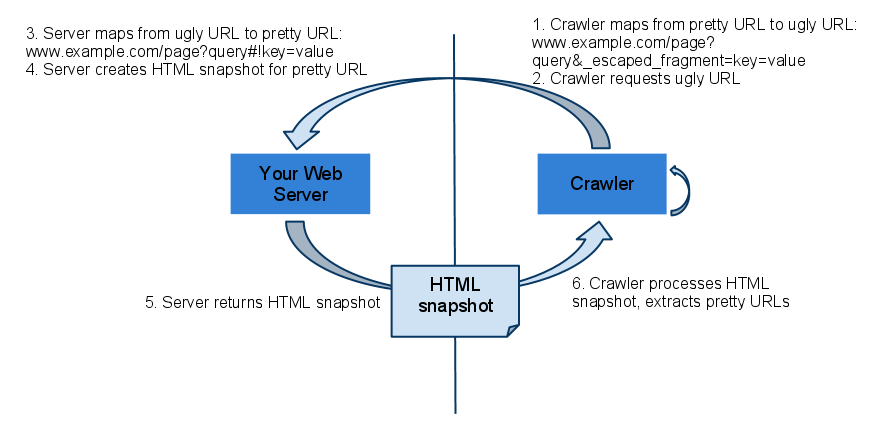
In 2009 Google introduced a workaround intended to make SPA SEO-friendly.
The scheme consisted of adding hashbang (#!) to the page’s URL; producing an HTML snapshot of the page (can be done via Prerender); feeding web spiders the page’s HTML version via the URL where “#!” is replaced with the “?_escaped_fragment_=” token.
As the result, crawlers would index the page’s content and serve the original URL in the search results.
The recent test by Bartosz Góralewicz has shown that Google is generally able to execute JavaScript on client-rendered applications built with various JS frameworks except for Angular.
At the same time, other search engines (which handle almost 37% of searches in the US) and social media bots aren’t as good at crawling
JavaScript as Google. So if you want to be ranked high in Baidu, Yandex, Bing, or Yahoo, don’t rely on their AJAX crawling capabilities.
Make sure that your SPA is indexable by using the methods I’ll describe below.
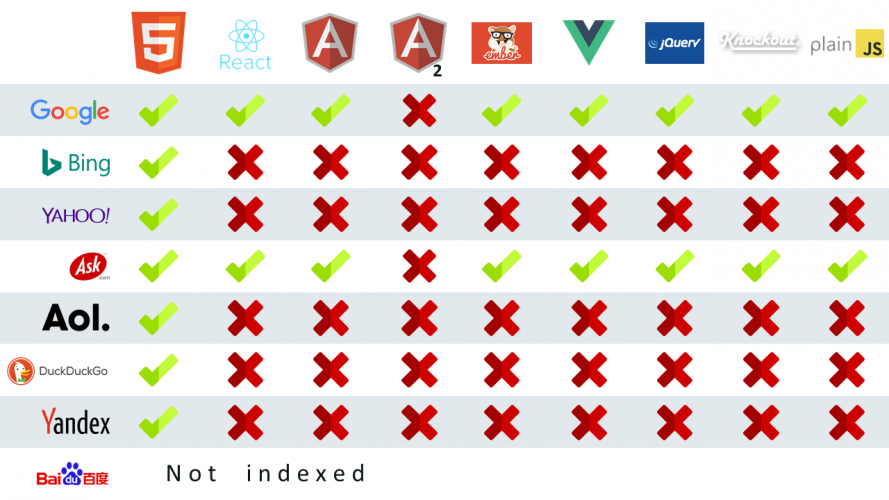
How search engines crawl sites built on various JS frameworks; source: moz.com
2. Use server-side rendering
Despite Google now claiming it can crawl JavaScript, it’s better to be safe than sorry. Hulu’s case (almost 60% visibility drop) shows that taking no precautions can have disastrous results. That’s why we at MindK employ server-side rendering to boost SPA discoverability.
You can take an application built on a client-side JavaScript framework like React, Angular, or Vue.js and render it to static HTML and CSS on your server.
When the user browser makes an initial request to the server, the browser will receive a completely rendered HTML content, not an empty HTML container as it happens with traditional SPAs. While JavaScript is still loading in the background, users will already see the HTML version of your site.
This will increase the perceived loading speed and improve the UX!
Web crawlers will also have access to the page’s complete HTML version that they can index and display in the search results.
On subsequent requests, your single page application will, of course, use the regular client-side rendering ensuring that the content loads fast for both the first and for the umpteenth times.
Further reading: how to set up server-side rendering for React, Angular, and Vue.js single-page applications.
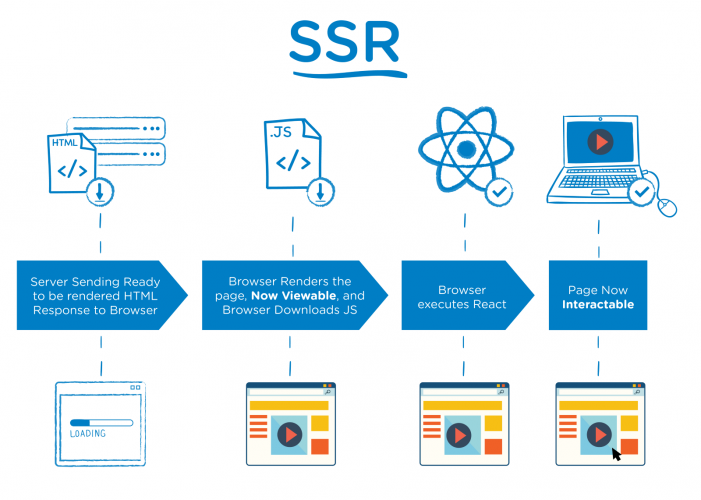
Source: Medium.com
3. Use progressive enhancement and feature detection.
Source: blog.teamtreehouse.com
Using progressive enhancement and feature detection is the current Google’s SEO recommendation for single page apps.
- First, create a simple HTML page that can be both accessed and indexed by web crawlers and seen by users.
- Then use feature detection to progressively enhance the experience with CSS and JavaScript. Detect the features supported by the user’s browser and enable/disable them accordingly. Check if the feature API are available and never employ browser’s user agent to enable/disable the application’s features. Remember to test your SPA for numerous browsers before launching it.
- Employ server-side or hybrid rendering to fetch your users the content upon first request. Make sure that deep linking works for your SPA. Never redirect your customers to your homepage instead of taking them to the deep-linked content.
- Use responsive design that accommodates multiple devices. Never serve different content to users and search engines. This rule applies even if you employ dynamic serving to change the site’s design for various devices.
- Don’t transition your old website to a progressive SPA in one go. Instead, develop it in iterations. Adding one feature at a time will allow you to see how each of them affects SEO.
- Use Search Console. It will also discover the existence of Structured Data, Rich Cards, Sitelinks, and AMPs.
- Add notations with Schema.org structured data. This allows you to sum up the paramount pieces of your content in a machine-readable format. You can, for example, specify the page’s data type (like stating that it’s a “Recipe”). Or you could list all the ingredients that make up the recipe. Just make sure that this metadata is, in fact, correct with Google’s tool for structured data testing. And never label your content with the wrong data type.
- Test your SPA for multiple browsers using tools like BrowserStack.com and Browserling.com.
- Optimize your SPA for speed before you’ve made it available to the public. Although Googlebot can wait for more than 5-20 seconds before indexing your page, few real users will wait that long.
What other steps can you take to optimize your SPA’s discoverability?
1. Draw up a complete list of pages on your website
SEO experts recommend creating a Sitemap.xml for any web application. Even after the announcement that Googlebot can crawl JavaScript applications, website owners continue reporting unindexed pages.
Sitemap.xml is a file that contains all the URLs for your application. You should use your Sitemap as a guide to make sure that crawlers haven’t turned a blind eye to some crucial piece of your app.
Note that Sitemaps need promotion. So add the following line to your robot.txt file. This way, Googlebot will know the location of your Sitemap. Afterwards, you should submit your Sitemap to Google Search Console which will trigger the indexing of your website.
You’ll have to add the <meta name=”fragment” content=”!”> tag at the top of your site to let Googlebot know that it is, in fact, an SPA.
2. Use the “Fetch as Google” tool
Google Search Console has the “Fetch as Google” option. Fetch as Google is incredibly useful for SPAs as it allows you to see what JS and CSS elements aren’t available for indexing. By using the tool, you may discover that the search engine displays your SPA incompletely or ignores its crucial features.
Type a page’s URL and get it fetched the way Google’s crawlers would do while indexing your site.
Running Google Search Console allows you to see your application through the crawler’s eyes and discover what additional steps you need to take to improve your search rankings.
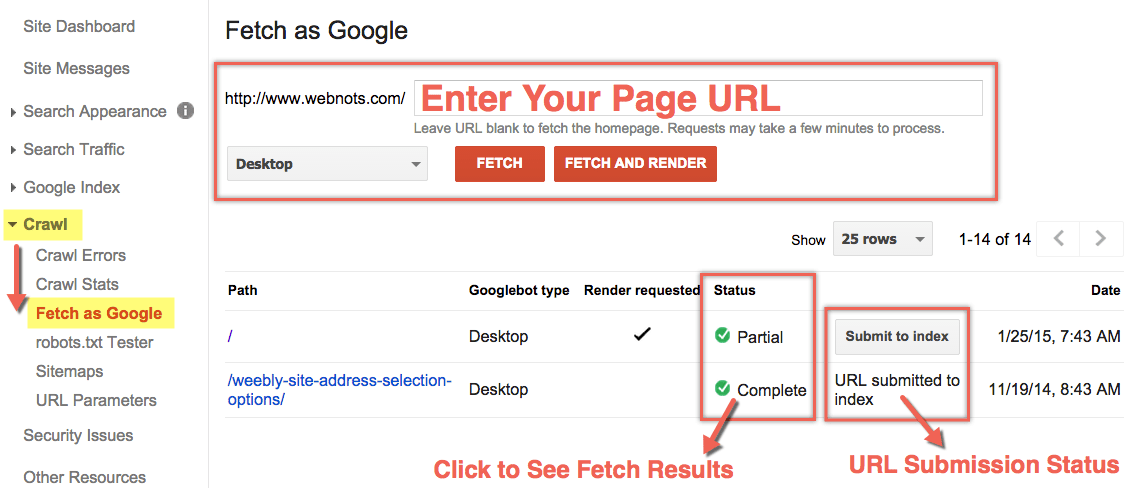
The Search Console’s “Fetch” option sends back the HTTP response from your page together with the complete download of its source code as seen by web spiders.
The “Fetch and Render” option sends back the HTTP response as well as two screenshots of the page: one as seen by Googlebot and another one through the eyes of your users. It also shows what resources Googlebot couldn’t get. This way you’ll make sure that none of the necessary resources like JS files, server responses, API and so on aren’t blocked by robots.txt.
Since Google depreciated the old AJAX crawling scheme, the sites that use it may run into unexpected issues. As a precaution, Google now recommends using the “Fetch and Render” tool to test the SPAs that have hashbangs or escaped fragment tags in their URLs.
So compare the results for the “#!” pages and “?_escaped_fragment_=” URLs to see if there’s any difference.
Once you fetch a page, a third option, “Request Indexing” becomes available. You can use it to start indexing without having to wait for the usual crawling cycles.
3. Use rel=canonical links
Not only the rel=canonical links can come in handy when you have several pages with the same content. They can also let crawlers know which part of the URL is mandatory and which isn’t.
For instance, this will allow Googlebot to detect if a query parameter affects the rendering of a page (pagination parameters like “?page=11”,) or not (tracking parameters like “utm_source=facebook”).
If you have a page that can be accessed via several URLs (as it often happens with e-commerce sites) or several pages with the duplicate content, make one of them canonical.
Pick the page you consider more important (or the one with the most visitors/links). Now add the rel=canonical link leading from non-canonical pages to the canonical one.
This way Google will know which version of your content is ‘official’ and count all the links to its duplicates as the links to this canonical page.
To benefit from the rel=canonical element, you’ll have to use dynamical URLs. Also, remember that canonical and Sitemap URLs have to be identical.
And remember to check if rel=canonical links lead to a real website, and robots.txt permit Googlebot to index your single page application.
4. Set up Google Analytics
Google Analytics is an important part of SEO efforts. It works by logging page views each time users arrive at your page. But with SPA there is no HTML response that would generate the pageview. To benefit from Google Analytics you’ll have to find another way.
One way to do this is via the Angulartics plugin. As single page applications load HTML dynamically, the plugin doesn’t use the standard tracking. Instead, Angulartics tracks the virtual pageview and records the whole user navigation throughout your SPA.
Another substitute for Google Analytics is Google Tag Manager.
5. Employ Open Graph and Twitter Cards
Social media shares can play a crucial role in your SEO link building efforts.
Implementing Twitter Cards will enable your SPA to have rich sharing on Twitter.
To enable correct sharing via Facebook, you should consider implementing Open Graph.
When somebody shares the link for the first time, FB’s spider crawls the page, gathers information about it and generates a visual object that will later be displayed on Facebook’s pages. Facebook’s Open Graph protocol allows one to optimize and structure the data people share via the social network. To make use of Open Graph, you have to add certain <meta> tags into <head> section of the HTML page you’d like to post to the social network.
The most useful Open Graph <meta> tags:
- og: title (names the page’s title);
- og: description (briefly describes what your content is about);
- og: type (specifies the datatype of the content);
- og: image (indicates the URL of the picture used to illustrate the page);
- og: url (specifies the page’s canonical URL).
You can use Facebook’s Debugger tool to test your OG tags.
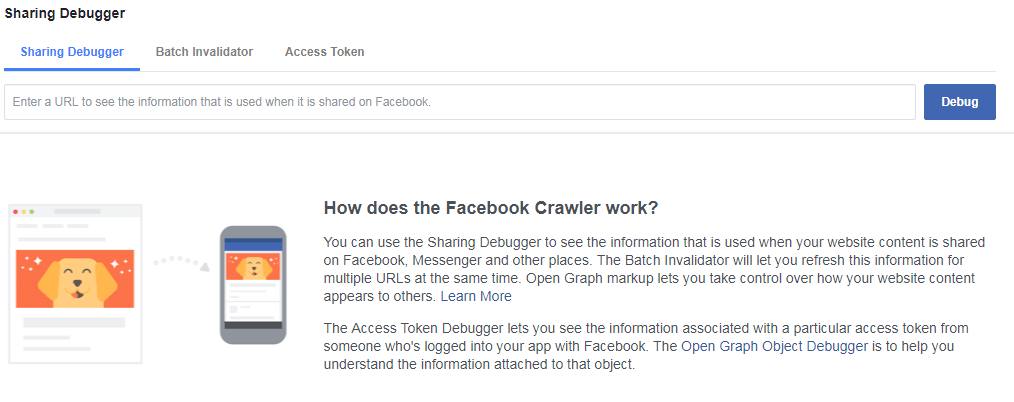
But this is not enough when dealing with single-page applications without server-side rendering.
Unlike Googlebot, Facebook’s crawlers can’t yet interpret JavaScript!
Even if you’ve added all the correct OG tags, the spiders will only fetch the plain HTML. As the result, you’ll get a post that nobody in their right mind would share:
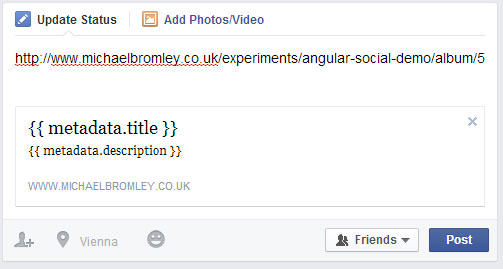
Source: www.michaelbromley.co.uk
One way to enable rich social sharing for SPAs is to create a conditional redirect that will serve the metadata to Facebook’s bots. This way, crawlers will get a static file instead of having to deal with JavaScript, and regular users will be redirected to the URL that has the actual content.
Conclusions
As you can see, building single page applications doesn’t necessary spell doom for search engine ratings. If you put enough effort, you can make your SPA SEO-friendly.
Just like any traditional web application.
Cutting-edge tech, such as progressive enhancement and server-side rendering for SPA, allows you to create awesome interactive experiences without sacrificing their discoverability.
And don’t forget about the general SEO recommendations like reducing the amount of JS files and server responses needed to render your pages, checking the server header responses, updating cache on the hubpages, or thinking through the solution to find pages with rendering problems.