
Long gone are the days when companies could produce an innovative feature and reap the benefits for years to come. Now they have to experiment at a breakneck pace to stay competitive. Even a few years ago Amazon deployed software every 11.6 seconds. DevOps is the approach that makes this speed possible.
What is DevOps? It is an entire philosophy that bridges Quality Assurance, development and operations teams. It uses a set of best DevOps practices and proven tools to automate software delivery. DevOps is one of the key ingredients that allowed companies like Amazon and Netflix to dominate their markets. At MindK, we tried the DevOps fundamentals about 6 years ago. Since then, it’s become the backbone of every project we do for our clients.
Here are the most valuable insights we learned while making DevOps work.
Table of contents:
- A culture of communication and collaboration
- Very frequent but small updates
- Continuous integration and delivery (CI/CD)
- Automated testing
- Microservices architecture
- Infrastructure automation
- Configuration management
- Security and policy as code
- Regular code reviews
- Monitoring and observability

1. A culture of communication and collaboration
A radical culture shift is one of the first DevOps stages. Many companies still work in siloed environments. They have different teams – developers, operations, QA – all with separate areas of responsibility. But you can’t work fast without cooperation and transparency.
The change should start with leadership. Some engineers often take the role of a DevOps evangelist that promotes the approach inside the company. From our experience at MindK, such people have to talk early and often with executives to secure buy-in. They need to communicate engineering wins in a language that’s accessible to business people.

Leadership provides the vision for the DevOps team. It has to create an atmosphere where it’s OK to fail and learn from failure. You should motivate the team, encourage them to ask questions, and support the individual behind the job.
DevOps culture also changes how developers think and operate. They need to take responsibility for their code all the way to production. You build it, you run it. This is only possible in truly cross-functional teams, favored by Agile development.
2. Very frequent, but small updates
DevOps appeared as a response to the business need for delivering value to customers at a higher speed. It has done for engineering what Agile did for project management. It’s impossible to separate the two practices.
Start with small cross-functional teams that make frequent but small updates. By releasing more often, the team can regularly review the progress, readjust their plans, and pivot following user feedback.
Kanban and Scrum are the two most popular Agile frameworks.
Kanban centers around a simple task management board. It is usually divided into 4 columns: to do, in progress, code review, and done. When out of work, an engineer can just take the highest-priority task from the backlog and move it across the board. Releases can happen as often as needed.
Scrum is a more formal approach. It splits the development into 2-week Sprints, each ending with a release of a working feature. One person on the development team – a Product Owner – acts as a user representative. Another – a Scrum Master – oversees the Scrum rituals:
- Planning Sessions before each Sprint.
- Daily Scrums – 5-minute meetings to discuss the team progress.
- Sprint Reviews with a demo for clients after each release.
- Sprint Retrospectives to review mistakes and plan improvements.
If you want to learn more about Agile, you can check the e-book we wrote that details everything you should know in under 1 hour.

3. Continuous Integration and Delivery (CI/CD)
DevOps strives to automate as much as possible. CI/CD are two DevOps methods that help you achieve that.
It all starts with Continuous Integration – a practice of merging code changes into a common repository as often as possible. The system then automatically compiles the code and runs some basic tests. Shifting left – or testing as early as possible – allows to discover more bugs and fix them at a lower cost.
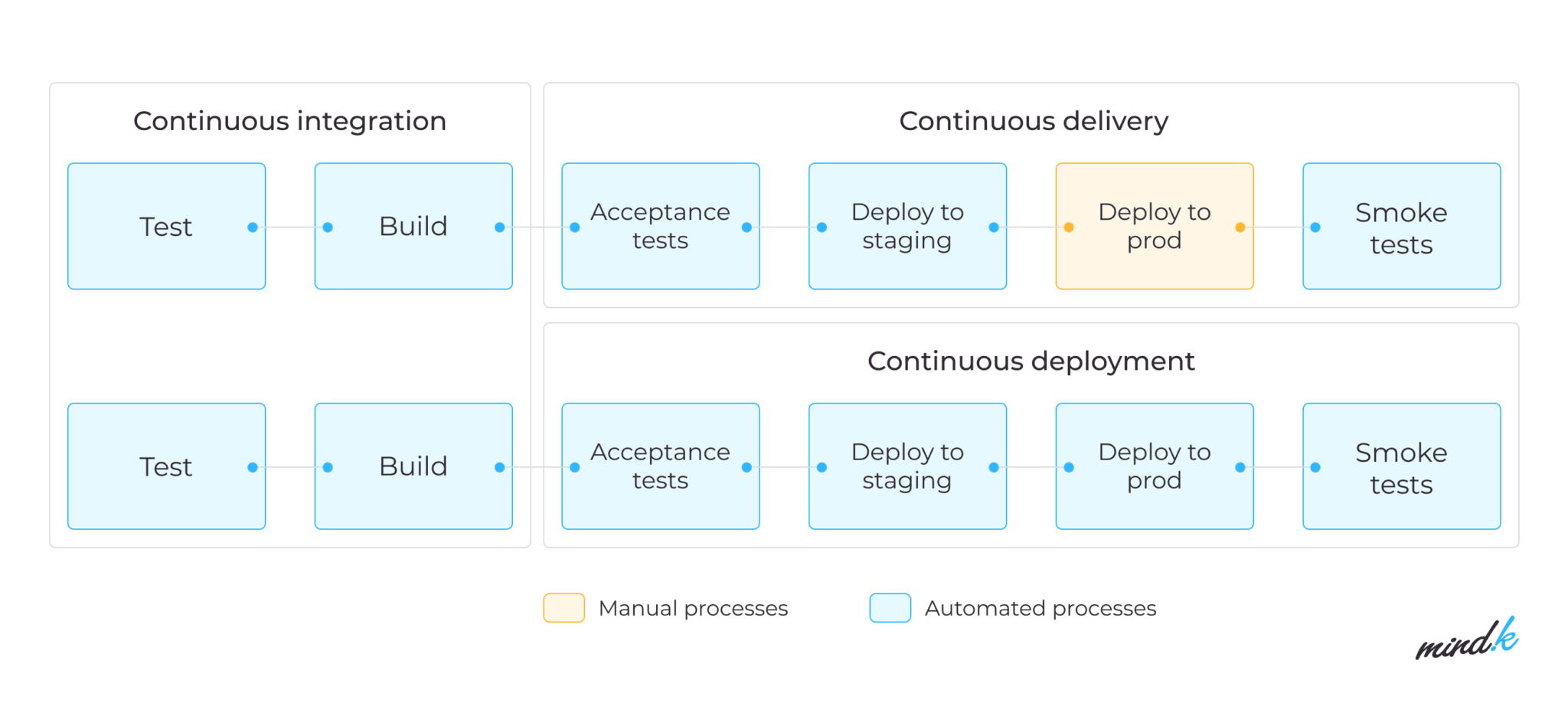
Continuous Delivery is the next evolution of this idea. It automatically compiles code, runs tests, and prepares it for a manual release. When CD works as planned, engineers always get a deployment-ready build artifact that has gone through the typical tests. This allows to release much more often.
 Implementing an automated CI/CD pipeline allows engineers to make quick deployments without involving the DevOps people. This came to light in one of our recent projects – a self-assessment app for choosing an optimal career path called Xelfer.
Implementing an automated CI/CD pipeline allows engineers to make quick deployments without involving the DevOps people. This came to light in one of our recent projects – a self-assessment app for choosing an optimal career path called Xelfer.
From the very start, our client agreed to follow the key DevOps practices described in this article. Our DevOps engineers came in early to design the project structure with separate environments for developers, QA, and production. They’ve created a CI/CD pipeline using Bitbucket Pipelines. Developers basically got a “button” they can press to deploy code after an automated build and test process.
Investing about 40 hours upfront allowed our developers to spend the next 2 years implementing new features without involving DevOps engineers.
The pipeline also supports Continuous Deployment – automatically deploying the code that passed all the tests. Deployment without human intervention might seem risky but you play it safe by using a well-designed pipeline and a blue/green deployment strategy. The latter involves running 2 identical production environments:
- The blue environment is for the current version of your product.
- The green environment is where you deploy any changes.
At first, all your traffic goes to the blue environment. After making a change, you slowly route the traffic towards the green environment until they switch places. This allows you to make rapid changes without downtime. We like to use Kubernetes containers to support blue/green deployments, lower operational costs, and improve fault tolerance in our projects.
4. Automated testing
CI/CD makes it necessary to test early and often. QA specialists need to finish testing new features before a 2-week feature release. They need to work faster as a part of a truly cross-functional team. And this brings the need for automated testing. Running tests during the compilation process allows engineers to discover bugs much earlier – and fix them at a fraction of the cost.

Data source: IBM Systems Sciences Institute
It’s impossible to automate all your tests, so prioritize the cases that provide the highest value:
- Unit tests validate the smallest units of code. They are the prime target of automation.
- Regression tests that make sure new updates don’t break the old code.
- Integration/API testing that validates the app’s business logic.
- UI tests are often the first thing people try to automate but the value this provides is quite low.
The best automated testing strategy is to have your CI/CD pipeline run at least one unit test and one acceptance test. You should pair them with some manual exploratory testing by experienced QA engineers.
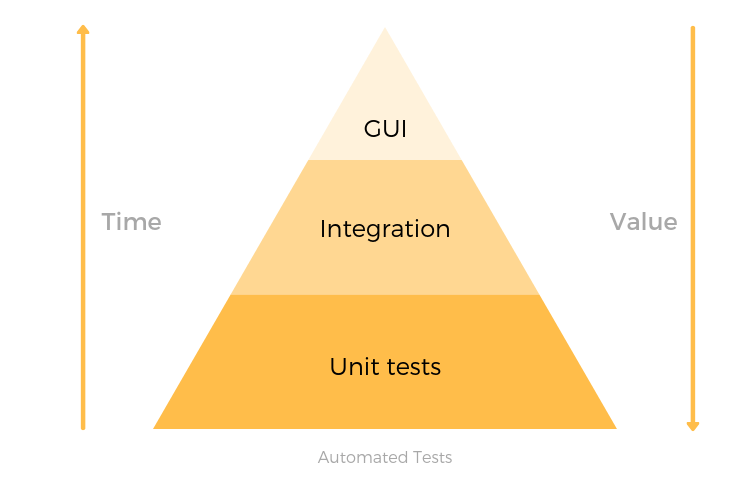
The testing pyramid shows the relationship between the time to automate a test and the value it provides
5. Microservices architecture
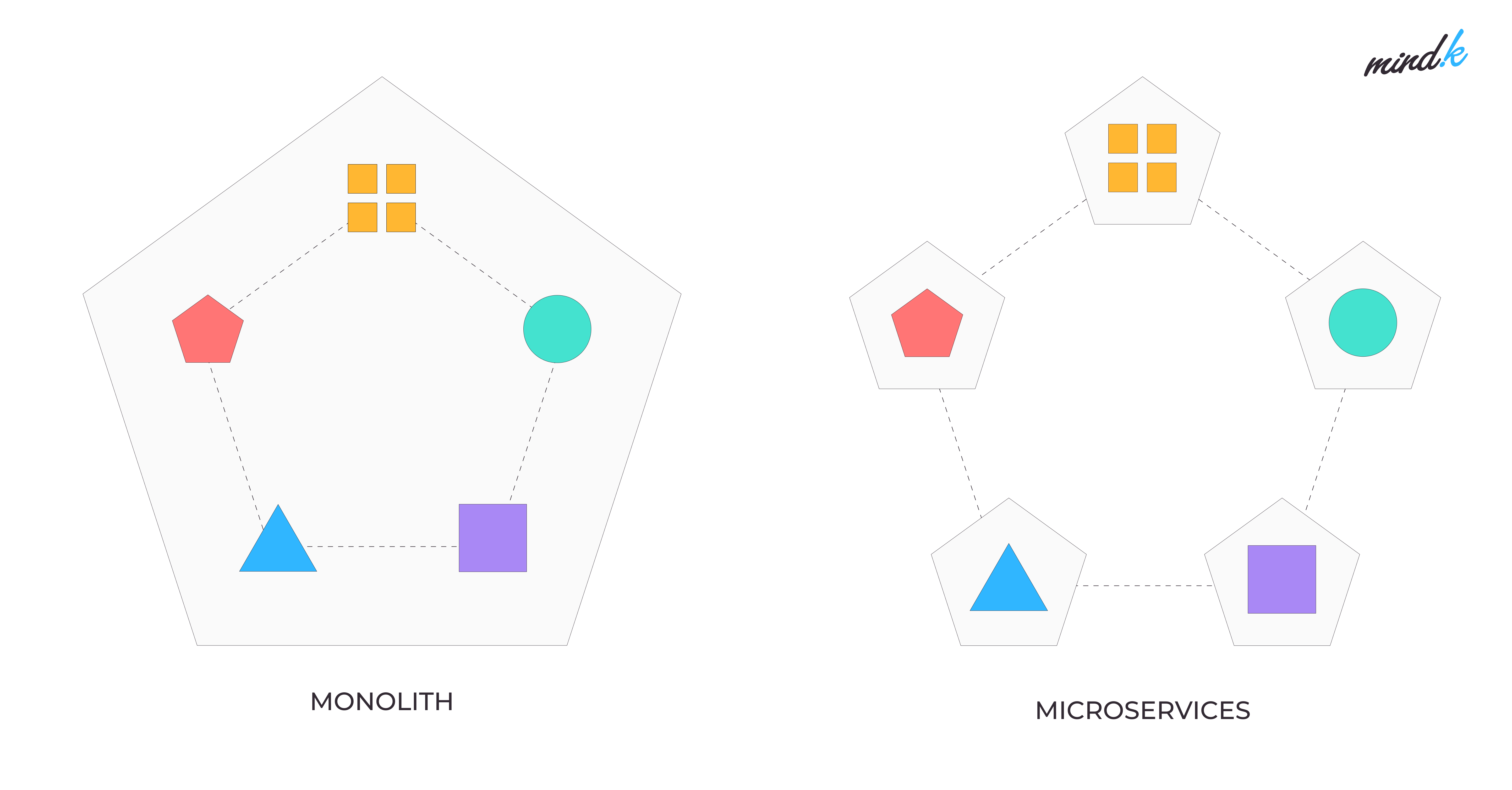
Traditionally, developers built software with a monolithic codebase. Such software typically has one interface, a single backend, and a database. As monolithic apps get larger, they become too complicated and unwieldy for rapid changes.
Microservices split larger applications into many independent modules or services. Every module represents a single feature. A service has its own business logic and a separate database connected with APIs (Application Programming Interfaces).
Each service is typically developed by a separate team. They can modify a module without affecting other services. Independent deployment and updating mean you can introduce features much faster. Coordination overhead is also smaller. This supports the Agile philosophy of small and frequent updates.
We first tested this approach on a large maintenance project for a US company. The team struggled with the legacy infrastructure as all changes required manual actions. What’s more, the company paid a ton of money for infrastructure without Amazon’s cost-saving options. Switching to microservices was the first step that allowed the team to introduce DevOps process automation and save up to $14,000 per month of infrastructure costs.
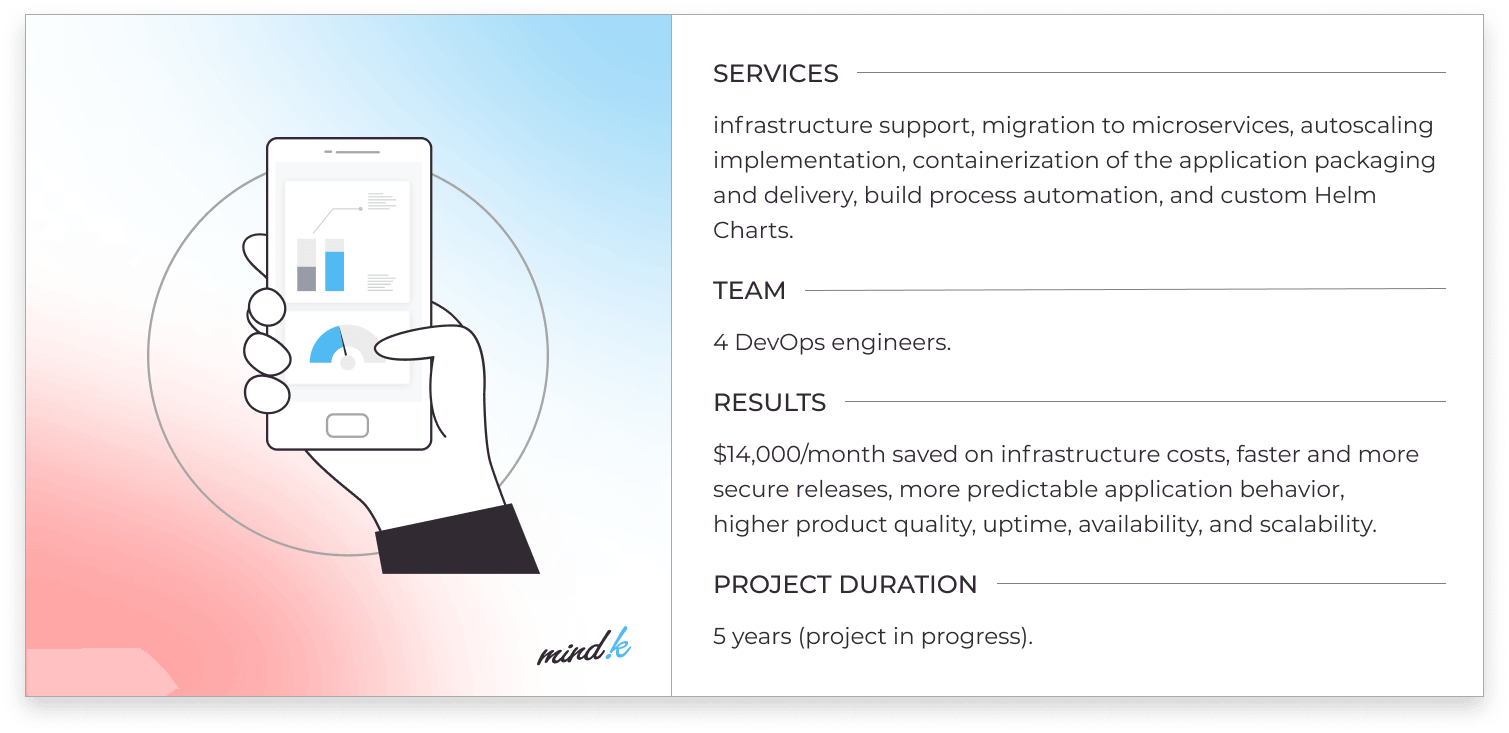
Optimized infrastructure for a leading reputation management company [read the case study]
6. Infrastructure automation
Manually configuring servers to provision infrastructure takes a lot of time. A better DevOps practice is to describe infrastructure as code (IaC) in configuration files. You can easily change, copy, and reuse config files. They can follow best practices from software development like continuous integration, version control, and traceability.
Interacting with infrastructure via code-based tools allows quick deployments using standardized patterns. This frees up the necessary time to develop new features.
Many of our new clients were already using the IaC approach by the time we started working on their projects. Yet, they sometimes have trouble implementing DevOps best practices like “one infrastructure code tree with differences represented by environment-specific variables“. This exact situation happened on a project for a fast-growing FinTech startup, resulting in risky and expensive maintenance.
Our DevOps engineers had to redesign the entire IaC using the best practices with the Terraform solution. Now modifying the config files automatically generates detailed infrastructure change plans the team can implement with minimum work. Using identical configurations during deployments removes human errors. Automated provisioning, administration, and management allow the team to dedicate more time to introduce new features.
7. Configuration management
Configuration management is another best practice in the DevOps model. It aims to keep infrastructure in the desired state at all times. This way, any changes will lead to predictable results. When there are no small, undocumented changes, your system becomes less vulnerable to security holes, inconsistencies, and performance drops.
In large applications, it’s almost impossible to manually identify components needing attention, plan remediation actions, and validate their realization. DevOps engineers can use code to automate configurations, making them standardized and repeatable. You can quickly provision a new server, maintain its desired state, and make changes much quicker.
8. Security and policy as code
Maintaining security and HIPAA/GDPR compliance can take a lot of time, especially with larger applications. There are now tools like Fugue and Snyk that can automate this tedious process.
We first tried out the Snyk security audit features during the Xelfer project I described above. The tool can automatically scan new code packages, Docker images, and any third-party components during builds and merge requests. It will flag any quality or security issues like known vulnerabilities or outdated libraries and provide suggestions on how to fix them. The tool will simply block any deployment that might compromise security.
Every organization has to test the software they produce to assess its quality. They can either make manual decisions during this process or implement automated policies to govern the decision-making. Policy as code uses code in a high-level language to define the rules for automated decision-making.
It can help developers manage access control in microservices, provision infrastructure in the cloud, and maintain compliance. Policy as code can automatically flag any non-compliant changes and automatically revert them to compliance.
Implementing security and policy as code requires a lot of effort from the DevOps team. That’s why leadership often hesitates to introduce these practices on smaller projects. But with larger applications, the benefits more than make up for the investments.
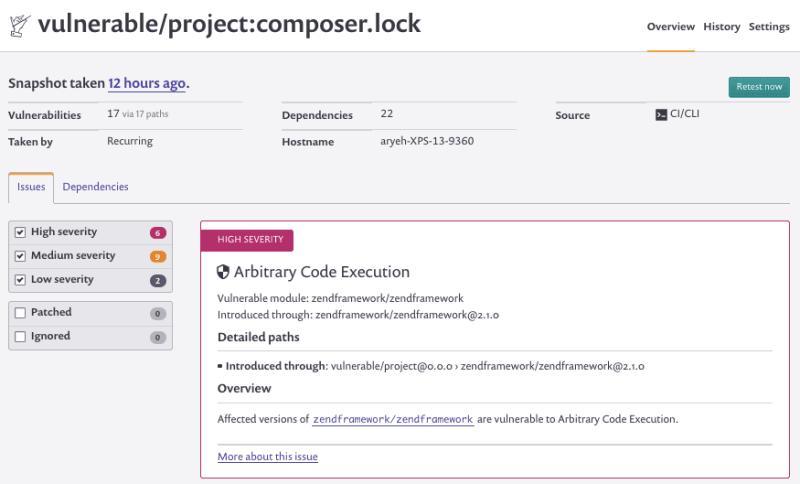
Snyk security alert. Source: Snyk.io
9. Regular code reviews
Speed is one of the main goals of DevOps. Yet, it must be properly balanced against quality and security. That’s why developers will often look at the code of their teammates looking for errors and inefficiencies.
At MindK, we followed a standard code review practice – Tech Leads check the code written by the less experienced developers. About 4 years ago, we switched to a new cross-review approach. This means that everyone on the team will spend some time of the day reviewing the coworkers’ code. This takes more time, but provides great benefits. The people that didn’t write a feature can learn how it functions. Reviewing the code of senior developers is a huge learning experience for new people.
Engineers that have direct experience with a feature can often point out more mistakes than even tech leads. Cross-review has immediately improved the code quality at our company. It can prevent situations where developers produce inefficient code that clients are happy about because it works as intended. The only requirement is to split larger features into smaller pull requests and review them once in 1-3 days.
10. Monitoring and observability
Old wisdom says that you can’t improve that which you don’t measure. This is especially important with automated DevOps pipelines. If something breaks and you don’t know about it, you lose all the benefits of automation.
Active monitoring is what allows discovery and remediation of any failures or performance dips before they impact customers. It uses a combination of logs, traces, and metrics. Most application components leave logs that describe the system performance over time. Recording, categorizing, and reviewing application logs allows you to discover the root causes of any issues or unforeseen changes. Traces keep track of the system’s logic flow. And metrics provide an objective way to gauge the application/team performance and see how it affects the user experience.
According to the most comprehensive research of DevOps practices by Google, 4 key metrics characterize the top-performing DevOps teams:
- Deployment frequency.
- Lead time for changes.
- Mean time to recovery (MTTR).
- Change failure rate.
You can learn more about these KPIs and how to measure them in our detailed article on key DevOps metrics.
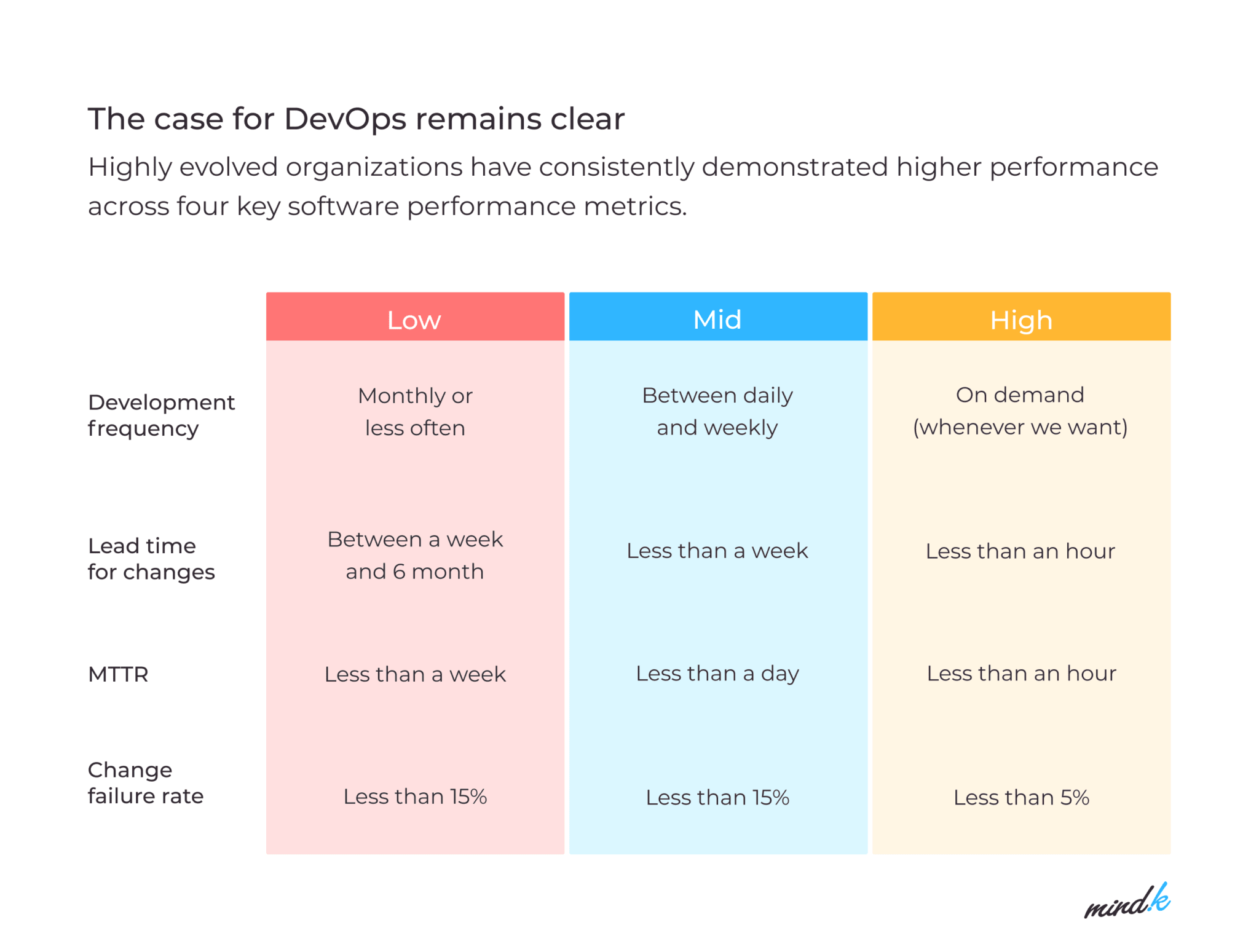
Source: 2021 State of DevOps report
Conclusion
The DevOps best practices I’ve discussed allow companies to deliver value at a previously unseen pace.
You can start by adopting a more open culture of collaboration and continuous learning. What follows are small and frequent updates with highly automated pipelines. Microservices and infrastructure automation help engineers provision the necessary resources for highly scalable applications. Regular code reviews and automated policies ensure excellent quality and security. Meanwhile, 24/7 monitoring provides timely alerts in case of failures and performance dips.
DevOps process improvement takes time but the benefits are more than worth it. Our 6 years of experience in DevOps outsourcing show that companies are often hesitant to invest in correct processes from the get-go. They end up losing a lot of time mitigating those initial errors. A small investment upfront will save you hundreds of hours down the line if you have enough expertise to make it work.
If you don’t know where to start or need some help with DevOps implementation, you can always rely on MindK. Just leave us a line and we’ll organize a free consultation with our DevOps experts.




