When businesses ask themselves, “What is important for a successful DevOps transformation?”, the first thing that comes to mind is adopting new technologies. Yet, despite experimenting with new tech, only 11% of teams are DevOps high-performers, according to the latest DORA research.
What holds them back is that DevOps is much more than a set of tools or technologies. It’s an entire philosophy that affects people, processes, and organizations as a whole.
As a software development firm, MindK has been practicing DevOps for more than 8 years to improve time to market, product quality, and team efficiency. In this article, you’ll find our key insights along with some actionable advice from the world’s top CTOs and Solution Architects.
Table of contents:
- Understand what DevOps is.
- Address the cultural challenges.
- Secure executive buy-in.
- Assess your current state.
- Select a small pilot project.
- Transition to a cloud-based infrastructure.
- Implement continuous integration.
- Enable continuous deployment.
- Implement infrastructure as code.
- Supplement your pipeline with automated monitoring.
- Standardize and scale.

#1 Understand what DevOps is
There is no single definition that can encompass the whole DevOps concept. According to Volker Will, the DevOps Technical Evangelism team lead at Microsoft, DevOps is all about enhancing the flow of development, from ideation to users and back. It is a methodology that unites IT Operations, Developers, and Quality Assurance professionals into small cross-functional teams that have all the necessary expertise to deliver working software.
DevOps impacts people just as much as it impacts the tools they use with heavy automation and improved collaboration. By talking to each other, Developers and Operations will learn faster, fail faster, and learn from this failure. So, how to transition to DevOps?
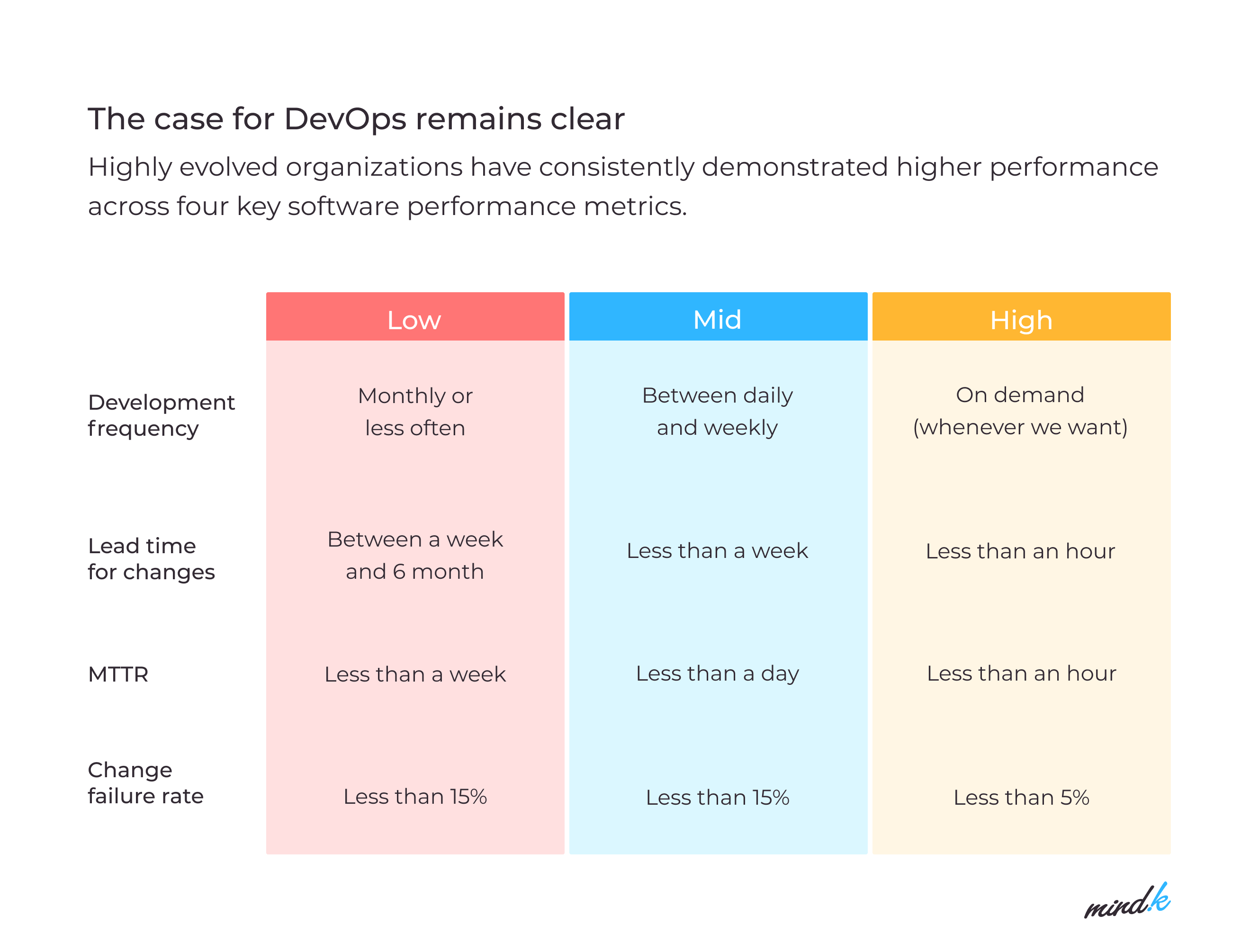
Source: 2021 State of DevOps report
#2Addressing the cultural challenges
You can’t find a technology or tool that will magically transform you into a DevOps organization. According to Jessica DeVita, a Solutions Architect at Chef Software, engineers understand how complex their environments are. So they try to find the right tool, a Holy Grail that will allow them to manage this complexity. But when they start moving faster with the new tools, things break much quicker.
And this is where we start to understand that DevOps involves a shift in culture, which is always a challenge. For most companies, it will start with dissolving the entrenched silos. The aim is to form small cross-functional teams that have all the necessary expertise to deliver a product, from start to finish.
That’s why Agile and DevOps transformation go hand in hand. You can, for example, adopt a Scrum methodology we use at MindK. It involves having short daily meetings where everybody answers three simple questions in a blameless environment:
- What have you accomplished yesterday?
- What will you do today?
- What are the blockers that hinder your progress?
These questions allow you to discuss other, non-code matters that reveal cultural barriers to the DevOps transformation process. Microsoft’s DevOps Evangelism team, for instance, used to practice events that would bring together the Dev and Ops crews for a couple of days. The team would explain the benefits those crews will get by working together. In many cases, these meetings were the first time developers started to understand their Operations colleagues.
Some engineers have never been asked: “What do you need for your job?” Getting them to answer such questions starts the conversation you need to have in order to standardize the way you deliver your applications to end-users.
#3 Secure executive buy-in for a DevOps transformation
Volker Will highlights the importance of getting adequate buy-in from all teams engaged in your DevOps project and the organization as a whole. You’ll need a full commitment of leadership, including time, resources, and money. Otherwise, your transition to DevOps might get derailed or abandoned early.
That’s why DevOps Evangelists play one of the most important (and often informal) roles in enterprise DevOps transformation. From our own experience at MindK, DevOps engineers need to talk early and frequently with their leadership. Communicate your wins, both big and small, using the language accessible to management. There’s no need to dive deep into the engineering terms to explain that users can now do something they couldn’t before.
According to Matt Bentley, a Solutions Engineer at Docker, a big question few companies consider at this point is: do you have time for change? If your teams don’t have much time, it’s better to scale back or use an external DevOps outsourcing service provider.

#3Assess your current situation
Many organizations fail their transition by imposing DevOps processes without understanding that DevOps isn’t just about tools or processes. Volker Will says that automation and tools are important, but they need to support your team objectives.
And how do you define those objectives? You need to make an honest evaluation of your current situation. To craft a DevOps transformation roadmap, think of everybody who takes part in delivering your product to end-users – including Developers, Operations, QA, Security, and so on.
Here are some of the questions to get you started:
- What people do you have on your team? Do they talk to each other?
- Have you implemented the right processes? What are the right processes for your team and your project?
- What is your software lifecycle? What does it look like?
- How do you apply changes, from development through production?
- What does your release process look like?
- What is your current definition of a release? Is it system-specific or do you have a company-wide outage for a whole night?
Eight years ago, most of the projects MindK made for our Norwegian partners had barely any DevOps practices. Almost all of them used the native LAMP stack, few benefited from some basic Docker container usage.
To introduce new components, our engineers would set up a Jenkins server on a local machine and use Debian packages. The build process involved a ton of plugins and custom scripts, which complicated maintenance. As a result, our releases were slow, unstable, and unpredictable.
At this point, we came to the conclusion that it’s a good idea to treat your DevOps transition as setting up a new service for people working on your software. It should be available 24/7. Everybody should have what they need to deliver software, from Development through Production. Then, introduce the other DevOps improvements discussed in this article to make your faster, predictable, and more stable.
#4Select a pilot project
Now that you know your current state, you can create your DevOps transition plan. What are your goals for a release? Doubling the number of deployments might be a good start, but it’s not specific enough. What does this signify for your business? Are you planning to double the amount of all deployments, or just in one specific project?
Volker Will says that good practice is to start with a small pilot project. Don’t try to change the whole organization overnight. Selling the DevOps transition to all stakeholders and teams across your organization will often require you to achieve success in production. So it’s a good idea to select one project (let’s call it “Minimum Viable Project”), and implement DevOps practices from development all the way to Production.
At our company, such a project was a custom CRM for the Norwegian Epilepsy Association. The pilot allowed us to deal with a multitude of technologies and barriers between different teams. We started by analyzing the entire release process, switching from local Jenkins servers to automated Bitbucket pipelines. Together with cloud migration, this allowed us to reduce costs on maintenance and introduction of new components.

#5 Transition to a cloud-based infrastructure
DevOps transition is much harder when you’re accustomed to on-premise infrastructure, according to Matt Bentley, a Solutions Engineer at Docker. Migrating to the cloud environment almost requires your teams to talk to each other.
Eight years ago, most MindK projects were hosted on dedicated servers. This didn’t allow us to automatically scale resources or create them on demand. Issues like backups, monitoring, alerting, and fault tolerance had to be realized from the ground up which cost our Operations team a lot of time.
One by one, we started migrating our projects to cloud infrastructure (AWS and Azure). This helped us reduce operational costs, increase the system availability, and fault tolerance, as well as implement the best DevOps practices we’ll discuss later in the article.
The benefits of DevOps, including faster time-to-market and greater efficiency, can be enhanced by the flexible cloud infrastructure. To take advantage of the cloud, you need to have repeatable processes. You should strive for a state where you almost don’t care where your infrastructure is so that you can deploy without ever visiting your office.
#6 Implement Continuous Integration
Many companies that struggle with digital transformation have their developers write scripts for each and every procedure needed to get your app into production. Changing anything requires manual edits, forcing you to script the entire delivery pipeline over and over.
Eight years ago, this was the case on our Norwegian projects. Our Operations team wasted much time on maintaining the build process. That’s why we decided to adopt a high-performing DevOps strategy which suggests that an engineer should own an app from development to production. The DevOps team should join the project at the requirements gathering stage and continue working through deployment and maintenance. The same team will then troubleshoot any issues, a role traditionally associated with Operations.
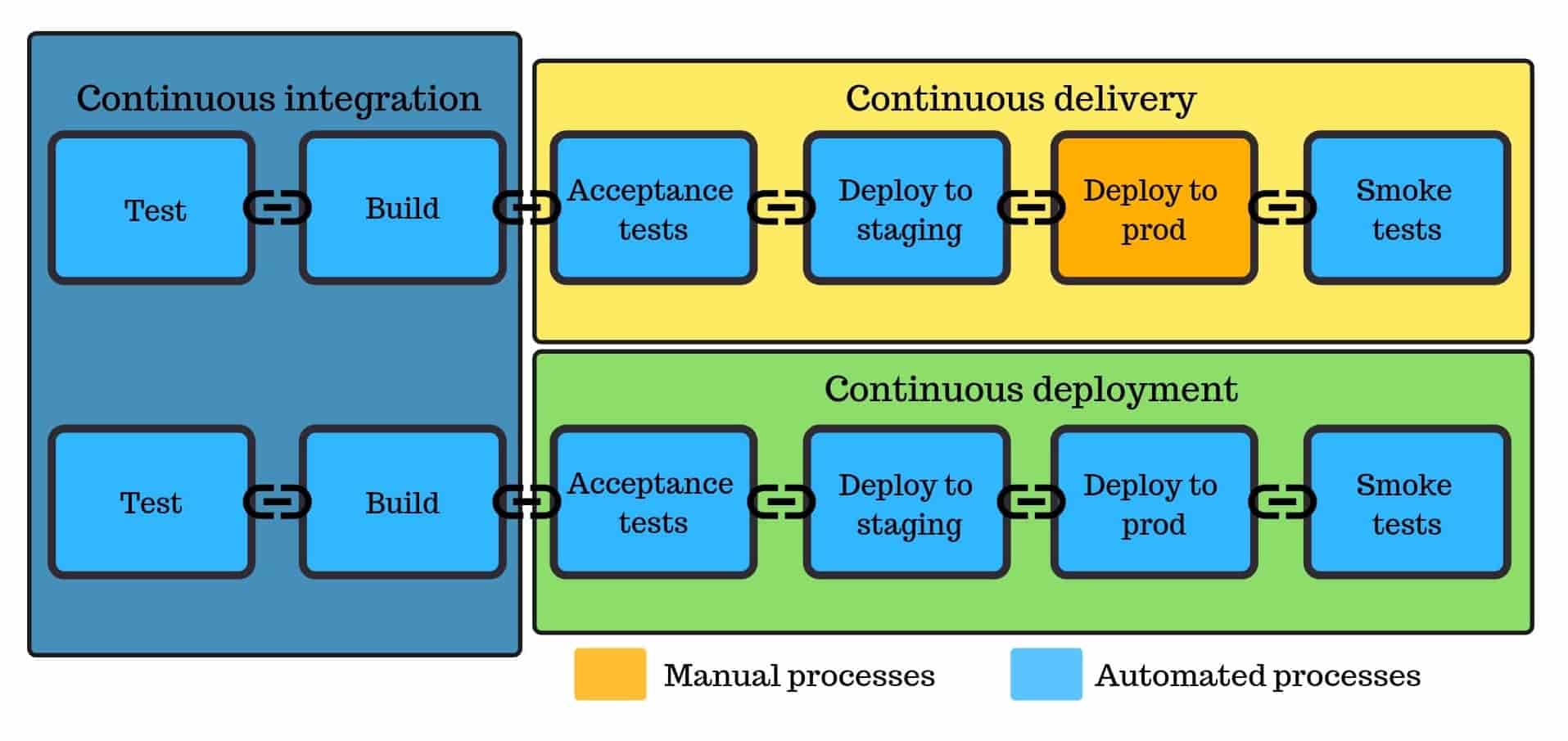
One way we support this transition is by creating an automated delivery pipeline that includes Continuous Integration, Development, Testing, and Deployment. Here’s how it works:
- A developer commits a change.
- This change sets off a compilation process on a build server.
- It then runs automated tests to ensure the high quality of the new code packages.
- If the tests are successful, the code is pushed to the test environment for review from the QA engineers.
- Once the code has been approved by the testers, it can be deployed to the production environment.
This approach requires you to test more and test often to ensure the high quality of your product. It integrates QA engineers into the development process to test any new features produced within short iterations. As a minimum, your automated deployment procedure should include a single unit test and a single acceptance test while leaving some time for manual exploratory testing.
#7 Improve to Continuous Deployment
You take a step further by automatically deploying to production the code that passes all your tests. Continuous deployment might seem too bold of a move as there’s no human verification before the deployment. But those worries are mostly insubstantial if you have a well-thought delivery pipeline. There’s also the possibility to implement granular controls – things like limiting some releases to trusted users or imposing specific time frames for deployments.
Over time, we migrated all our Jenkins builds to Bitbucket pipelines and GitHub Actions. This made our releases faster, more predictable, secure, and controlled.
To reduce risks with automated CI/CD pipelines, you can use a strategy known as blue/green deployments. In this approach, you have two identical production environments. Your current version of software runs on the blue environment. Any change you make gets deployed to the green environment. Initially, this new version gets only a small fraction of the traffic that gets increased with time. This allows you to gradually introduce new changes without affecting the system’s downtime.
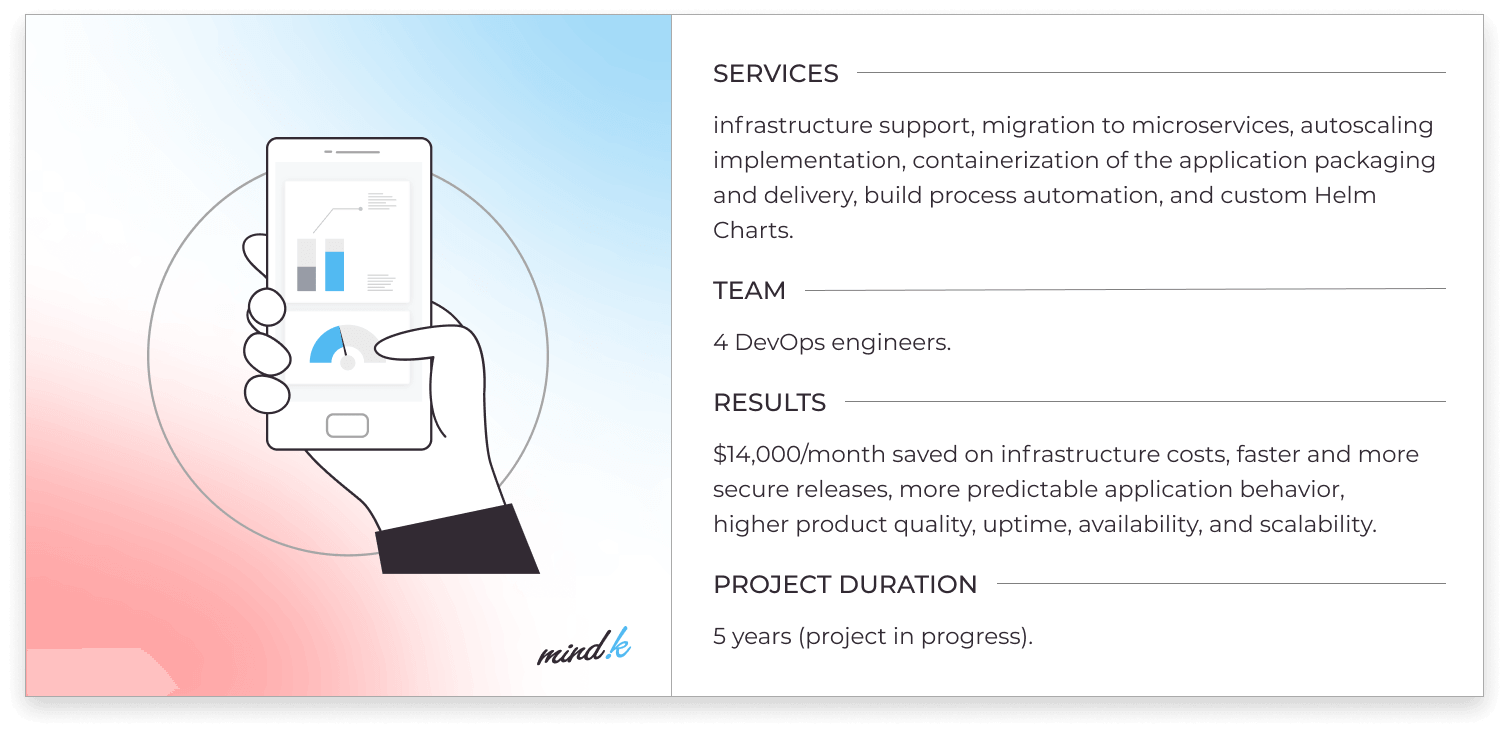
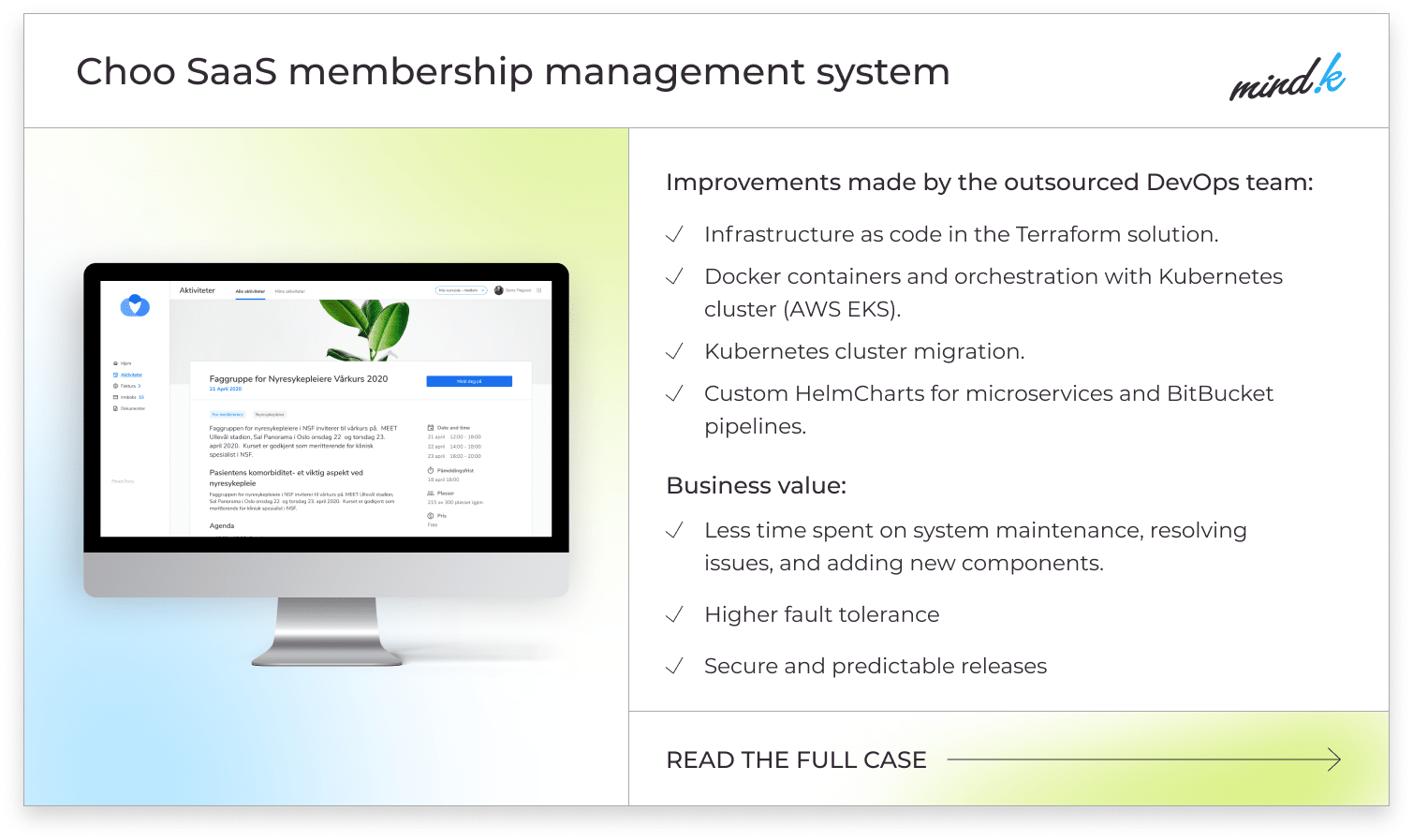
Containerization with Kubernetes is a technology that powers continuous blue/green deployment at MindK. As demonstrated by the Choo i Skyen project for our Norwegian partners, it can lower operational expenses, increase the system’s fault tolerance, and improve scalability.
#7 Implement Infrastructure as Code
Manually configuring servers to provision infrastructure can cost hundreds of man-hours for your Operations team. A far better approach is to describe your infrastructure as code using a special configuration language. This code is then stored in configuration files that are easy to modify, duplicate and reuse to provision any kind of infrastructure for your project.
Infrastructure as code allowed us to apply complex infrastructure changes with minimal work. The process of introducing a new DevOps engineer into the team becomes much simpler. Storing everything in versioned files makes it easier to trace changes which is great for compliance audits. This approach removes the need for manual provisioning, management, and administration, saving our clients a great deal of time for building new features.

Infrastructure as code optimization for a fast-growing European FinTech [explore the case]
#8 Supplement your pipeline with automated monitoring
If you want to benefit from CI/CD automation and blue/green deployment, you need continuous monitoring. Measuring your success is important to secure a continuous buy-in for your DevOps program according to Matt Bentley, a Solutions Engineer at Docker.
The first thing to do is define the DevOps metrics you want to track. As your resources are often limited, it’s crucial to focus on the most important areas:
- Development metrics like the code change frequency, number of new features, the number of defects detected/fixed in production, and so on.
- Automated alerts for deployment failures, security & compliance issues.
- Application performance metrics, like errors, throughput, Queue Time, Response Times, Apdex score of user satisfaction, and so on.
- User activity metrics, like resource usage and behavior patterns.
- Server health metrics like uptime, error rates, CPU/memory usage, and so on.
With accurate data on your current situation, you’ll be able to see whether your next iteration has moved your metrics towards your success goals.
#9 Scale up your DevOps transformation
Implementing a small pilot project is an important step towards the DevOps transition. The next stage involves standardizing your delivery processes to achieve true scale. With detailed releases and measurable objectives, you can move from a path of trial and error to a more systematic and repeatable approach.
By standardizing your DevOps service, you’ll be able to release more often and efficiently. By setting up correct objectives and measuring the relevant KPIs, you’ll be able to gauge your effectiveness and make well-educated improvements to your DevOps transformation roadmap.
DevOps is a journey and engineers can take it by working in small increments, making their work visible, and adopting a blameless culture. Failure is essential to learning, according to Jessica DeVita of Chef Software. So get ready to fail, get back on your feet, and take those lessons to your next iterations.
Conclusion
DevOps is not only about technology, tools, and automation. It’s a whole philosophy that affects people, processes, and organizations. So, what is important for a successful DevOps transition?
- Start by dissolving silos.
- Adopt a more Agile approach to development.
- Ensure management & team buy-in.
- Honestly assess your current state.
- Select a small pilot project.
- Set the right objectives and KPIs to measure success.
- Treat your DevOps as a new service.
- Monitor your performance.
- Standardize and scale.
This is a DevOps transformation plan we followed for the past 8 years at MindK. We’ve helped dozens of companies go from no DevOps to mature automation that provides time-to-market, higher product quality, and lower operational costs.
So drop us a line if you want to start your DevOps transformation with a free consultation.





