

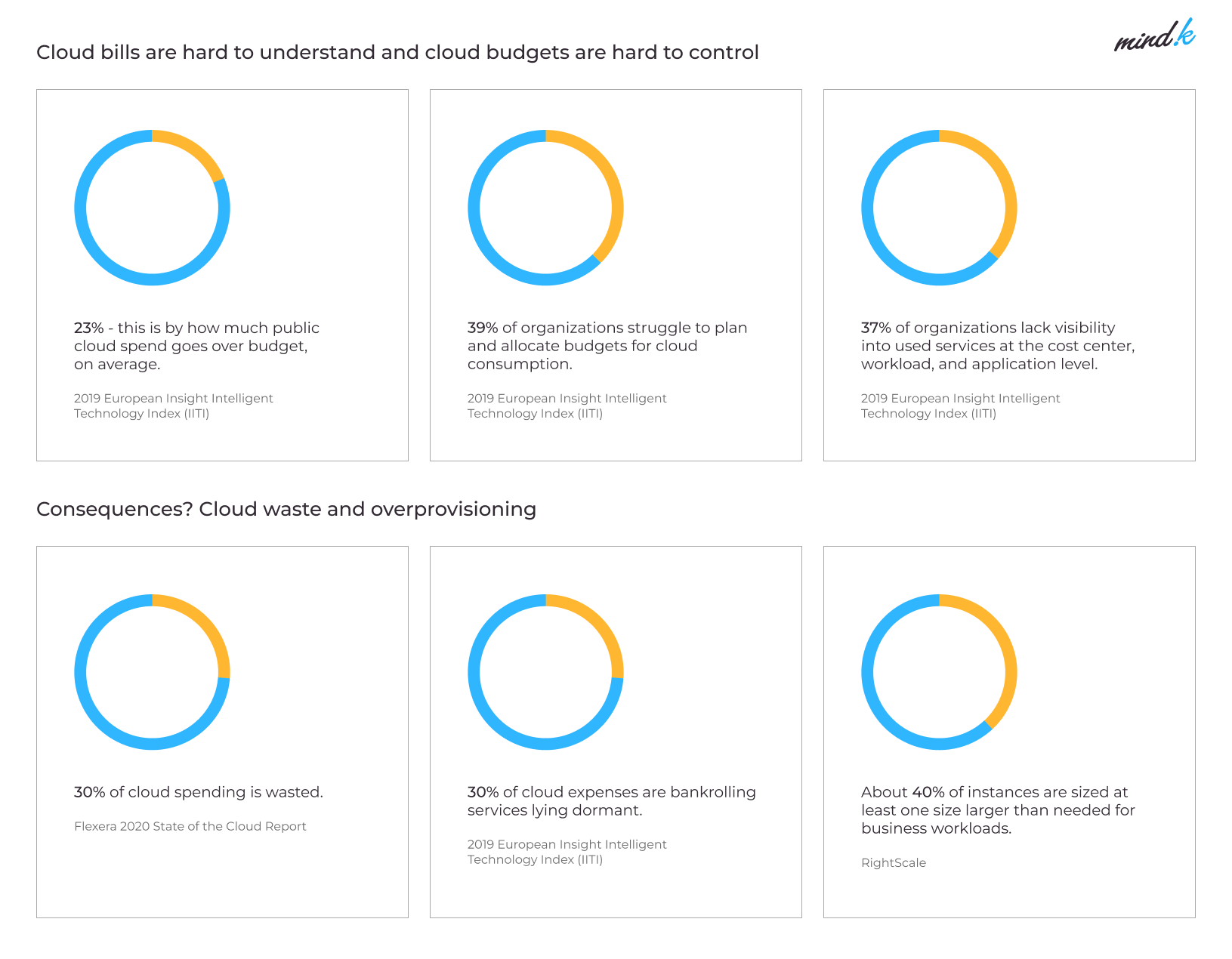
Cloud costs can be unpredictable, volatile, and hard to understand. Engineers at Adobe once burned through $80,000 of cash in a single day on Microsoft Azure. Five years ago, another SaaS company was overpaying AWS “just” $14,000 a month. Intervention from our DevOps team saved them over $840,000!
Those cases aren’t exceptions. From our experience at MindK, most SaaS companies waste about a third of their cloud spending, so learning how to reduce cloud costs is essential. Today, we’ll share some of the most efficient cloud cost optimization hacks from MindK’s DevOps engineers.
Table of contents:
- Why cloud costs can be hard to control
- Main contributors to the sky-high cloud costs
- Top 10 steps to reduce cloud costs in 2023

Why cloud costs can be hard to control
You often hear horror stories of startups wasting half of their budget while testing some obscure feature in Amazon Web Services (AWS). Just check out how the Bay Area startup Milkie Way lost $72,000 in just a few hours testing Google Firebase with Cloud Run. This simple mistake almost bankrupted the company in 2020. So, how can this happen?
It can be difficult to predict your cloud costs ahead of time as the billing depends on your actual usage. Fortunately, each cloud provider offers a set of tools you can use to forecast your expenses:
Now, the cloud bills themselves can be hard to decipher. Each cloud service has a different billing metric tied to it. To understand the billing principles, navigate to the AWS Billing and Cost Management Dashboard. Then, open the Cost Explorer, group the costs by specific attributes like resources per region/service, and generate a report.
This is a lot of manual work even if you only have a single team using one cloud platform. If another team at your company uses Microsoft Azure, you might discover that your bills look completely different. That’s why cloud pricing might seem obtuse, even for experienced engineers.

Source: cast.ai
Main contributors to the sky-high cloud costs
From my experience, cloud cost control becomes critical for larger long-term projects. Unlike startups that focus on delivering features as soon as possible, such teams can spare some time to address their growing cloud expenses.
1. Orphaned resources
It’s really easy for developers to create new resources in the cloud. And it’s just as easy to forget about them. The thing is, your cloud provider will still bill you for these unused resources.
Just imagine your average FinTech project with a team of 30 engineers. They’ve been building and maintaining the codebase for many years. All these people keep spinning up AWS instances to test new features, Lambda functions, S3 buckets, and third-party integrations. So the number of these resources keeps growing over time.
Now imagine that some of these developers have left your FinTech company or moved to another department. Now nobody knows for sure which of these “temporary” resources are necessary. After all, nobody wants to crash the development environment for the entire team.
2. Unaccounted storage costs
You pay for each Gigabyte of data in cloud-based storage services like Amazon S3. Everybody knows that. Yet some engineers overlook that input/output operations also contribute to your cloud bills. This goes against the instincts of developers who tend to use lots of read/write operations while building and testing their apps.
But the problem goes even deeper.
On the type of projects I’ve described above, you often see storage that’s clogged with unnecessary files, backups, snapshots, logs, and so on. This is especially bad for FinTech companies that have to keep logs for audit purposes of all transactions that happened in the past 3 years.
You could, of course, change some types of storage to cheaper options, and implement the rotation of logs, backups, and snapshots. Non-Frequent Access Storage, for example, is great for files you need to archive. Just make a request whenever you need to retrieve them – and access the logs in about 5 hours. As the retrieval isn’t instantaneous, the storage is much cheaper – an ideal option if you need to prepare for a FinTech audit ahead of time. But things like making a high-quality rotation – creating backups at specific times, erasing files if they are stored more than X days – require you to add an additional policy.
3. No Infrastructure as Code (IaC)
The problems I’ve described above usually arise when the team doesn’t use Infrastructure as Code (IaC). In such cases, all the resources need to be created manually. People with varying levels of experience spin up various resources, forget about them, or leave the company. No wonder it’s difficult to understand why some of these resources were created or how they interact with other parts of the product.
The situation gets worse if the person who should make sense of your cloud infrastructure is a junior DevOps engineer. Or even worse – a developer. Now you have to pay them weeks worth of salary to solve an issue that could’ve been completed in a couple of hours by an experienced DevOps specialist.
4. No autoscaling
Cloud-based applications rarely have steady usage. Your resource needs might vary through the day with sudden spikes threatening to overwhelm your servers. Without autoscaling, your teams need to account for the maximum expected load when spinning up resources. This can end up quite costly as you keep paying for the resources you don’t use. And idling instances aren’t free!
5. Lack of formal product discovery
Stakeholders tend to have rather vague requirements at the start of a new project. Without formal system requirements, a development team has to make assumptions about future functionality and scaling. Some of these assumptions might prove to be flat-out wrong. Such architectural blunders can whack you from behind as uncontrolled cloud costs. They can lead to poor scalability, limited customization, and the accumulation of painful tech debt. If any of these problems are true for your company, you’ll benefit greatly from software architecture consulting services with companies like MindK:
- Launch an audit of your existing architecture.
- Select an optimal tech stack for the task at hand.
- Create a transformation roadmap and a cloud cost management strategy.
- Help you implement them in a cost-effective way.

Top 10 steps to reduce cloud costs in 2023
Cloud is only cheaper if you implement it correctly. The paradox is that smaller startup projects often can’t justify spending precious time optimizing their cloud infrastructure. Meanwhile, older enterprise projects usually require investing in some major reworks to optimize cloud costs. Yet, the game is totally worth the candles.
Let’s look at the main steps in a typical cloud cost optimization plan.
#1 Run an infrastructure audit
On the kind of projects I’ve described above it can be very difficult to get to the root cause of high cloud costs.
In such cases, the recommendation is to start with a DevOps audit. During this audit, a cloud engineer should analyze:
- Your infrastructure.
- The team’s workflow.
- How it works with the project.
- How the team makes releases.
- Who is responsible for certain parts of the project, and so on.
An infrastructure audit involves a ton of communication with internal stakeholders. How does the system work? Why do we use those resources? Do we need them all? Which ones can we remove without hurting the system? Answering these questions will help you understand the causes of creeping cloud costs.
After the audit, you’ll be able to make carefully weighed decisions on what to optimize on the project.
#2 Improve the project’s architecture
Here’s a picture I’ve seen on many projects. The entire application has been sitting on a low-cost dedicated data center for many years (you can easily buy a 32GB Hetzner server for $120). As time goes by, the project grows and its requirements change. If the entire application lives on a single service and something works in a sub-optimal way, the whole system suffers.
Now, there’s a way to solve this issue with microservices. This approach allows you to separate a large monolithic application into smaller modules that can work independently from each other. These services live on separate virtual machines – Docker containers, Kubernetes clusters, and so on. The main benefit of such an approach is the following. If one service goes down or consumes too many resources, the rest of the product works just fine.
Yet, you can’t just take a monolith on a dedicated server and turn it into a cloud-native solution. Using practices like DevOps, Kubernetes, and microservices requires refactoring the product. Not all stakeholders are ready to pay for the developer’s time. So they often just move an unoptimized service to an on-demand instance of comparable size.
Let’s say, this instance performs a 10-minute task that needs 32GB of memory once a day. Such an instance will easily cost you $200 a month. But you can tweak the application’s logic, create Lambda functions or move the application to a Kubernetes cluster. This way, you can create an instance that works for 10 minutes a day to solve this specific task and then spins itself down. The cost savings could be enormous.
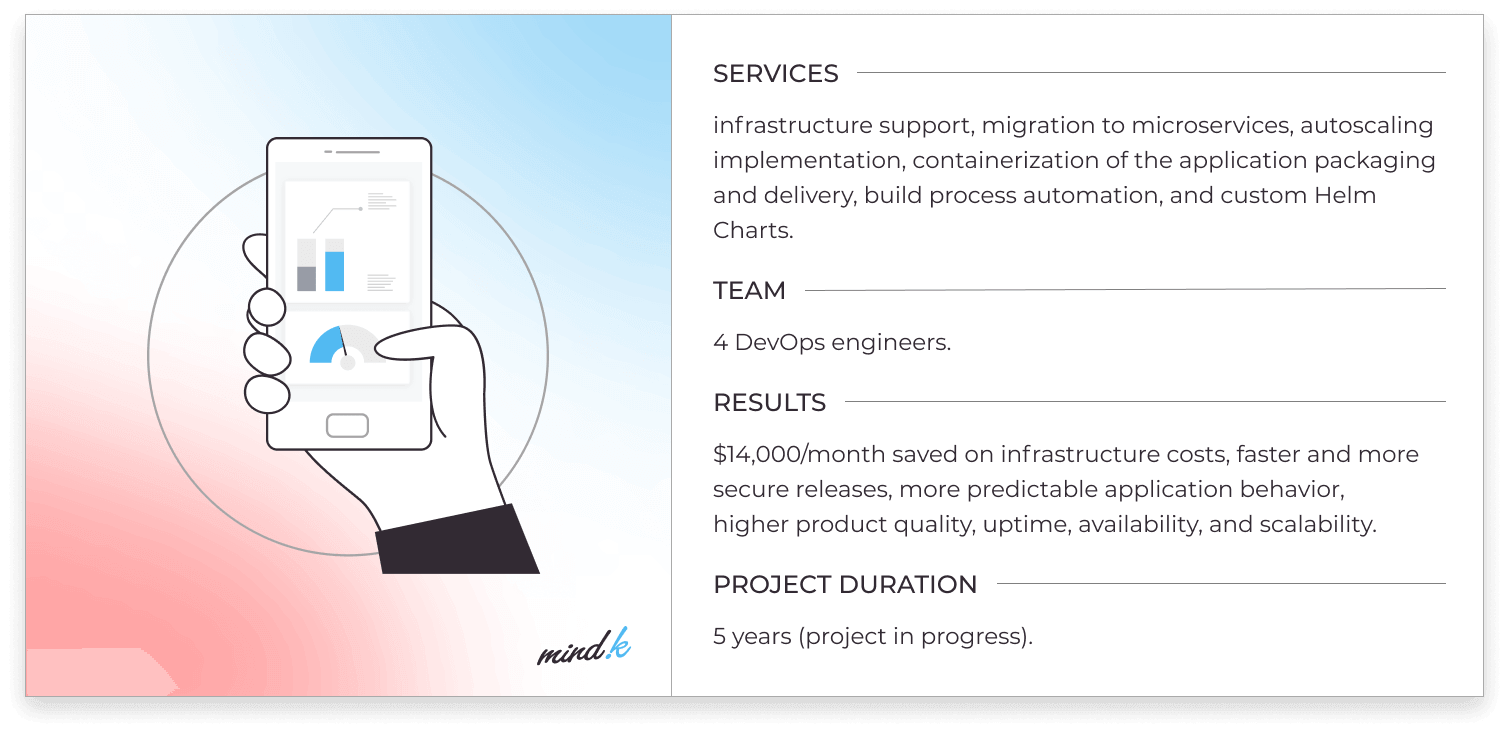
Read how microservice architecture reduced cloud costs and improved scalability for a major SaaS company
#3 Implement Infrastructure as Code
IaC describes all the resources you need to create as code in a special configuration language. You can store everything in one file and set up a policy that says the team must add all new cloud resources only via IaC. Proper versioning allows you to see who created a resource, for what purpose, how they were altered, how they interact, and so on.
You can easily duplicate the infrastructure – just copy a couple of configs, deploy the code and spin up hundreds of resources in a single click. This will save a lot of time on creating and managing all these resources manually.
That’s why IaC allows you to save money not only on cloud resources, but also on operational costs.
You can choose an IaC service that’s specific to one cloud provider like AWS Cloud Formation, or go for multi-cloud solutions like Terraform. The latter allows you to write infrastructure using a similar syntax for different cloud platforms. Terraform then uses different drivers (called providers) that translate your code to the cloud platform’s API. Tools like Terraform allow you to learn how to work with a cloud provider like AWS once and later migrate the application to Google Cloud or Microsoft Azure.
I’ve often seen projects that were only partially covered by IaC. In such cases, you need to research the manually created objects, how they interact with the rest of the system and import them to the Terraform code one by one.

Check out how MindK has optimized Infrastructure as Code for a fast-growing European FinTech [explore the case]
#4 Add autoscaling
Autoscaling allows you to dynamically request the exact amount of resources you need at the moment. You can select several smaller instances and set up load monitoring. It will automatically add new resources when you experience traffic spikes or start to consume more memory/CPU power.
When the load goes down, the application will remove unnecessary resources.
For legacy, non-cloud-native projects, this often requires refactoring the application and changing its architecture. For new projects, you’ll have to think about autoscaling from the very start. This will allow you to avoid situations in which you’ve been building features for a whole year before noticing your application getting unresponsive and cloud bills spinning out of control. Fixing problems at this stage often requires reworking your infrastructure logic.

#5 Use Saving Plans and Spot Instances
AWS offers several options for buying cloud compute – On Demand, Scheduled, Reserved Instances, Savings Plans, Spot Instances, and others. All cloud providers offer similar “pricing tiers”. And as it often goes, you can save quite a bit by using volume discounts and committing to purchase the provider’s services for a year or more.
Amazon EC2 Spot Instances allow you to use spare EC2 resources at huge discounts. From our experience, they can save up to 60% of your cloud costs. A good case in point is Choo – a custom CRM and membership management system we recently migrated to the cloud. Using Spot instances brought down the costs from $3,000 to $2000 a month.
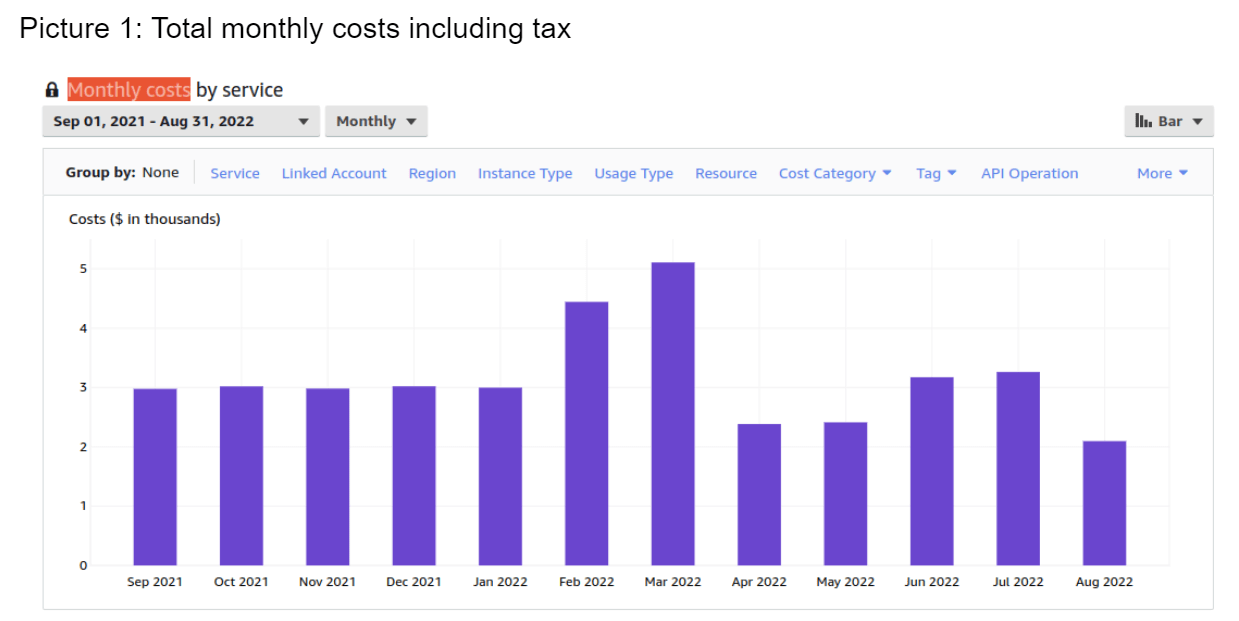
The increased cost in February, March, June, and July is due to the work with the cloud environments.
Spot Instances allow you to create a pool of similar instance types you want to request using an API. But there’s a catch. Amazon can give the instance you use to another client at any time. The API will signal that your instance will shut down in 5 minutes. In exchange, AWS will give you a similar instance of another type.
That’s why your product should be built to tolerate such instance rotation. For this, you’ll need Kubernetes clusters with dynamically connected Spot Instances – worker nodes that can process your product. Every service should live in several instances. So when an instance goes down, the service will continue to work.
AWS Saving Plans allows you to save another 30% by committing to pay $X/hour for a period of one or three years. This pricing tier has 3 variants:
- No upfront payment (monthly billing, the most expensive),
- Partial upfront (pay half the sum in one go), and
- All upfront (the cheapest option).
On the Choo in the Sky project I mentioned above, the 1-year commitment, no upfront, t3a type Saving Plan cut the client’s costs by around 30%. This figure will grow as the consumption of this type of resource increases. Since not all product services can run on Spot Instances, we are still forced to use a certain number of on-demand.
You can switch to a Saving Plan in just a couple of clicks. But making a thoughtful decision on which plan to buy, requires analyzing at least a couple of months of usage statistics, your infrastructure, and instance types. It’s easy to see why people don’t always want to delve into this data and continue to pay for the on-demand instances.
Choo membership management system [read the case study]
#6 Be careful about your storage type selection
Amazon S3 is by far the most popular type of cloud storage in the world. It’s simple to use, works great with the Amazon ecosystem, and stores a ton of data. Yet, some of your S3 buckets might be over- or underused. So consider different storage tiers when using the S3 service.
If you’re unsure about the optimal choice, you can always select the S3 Intelligent Tiering. This storage class accounts for your usage patterns to pick an optimal storage tier.
Amazon S3 Bucket explained. Source: AWS
Various database and search services from Amazon use the same principle as Saving Plans. Choo in the Sky project used on-demand RDS instances for its database services. This cost us about $1360 a year. By using RDS Reserved Instances (1-year commitment), we managed to bring down our database costs by 36%.
By far the biggest drain on the client’s budget was Amazon’s OpenSearch service – over $550 a month. By choosing the All upfront option, we cut these costs by almost x3.2!
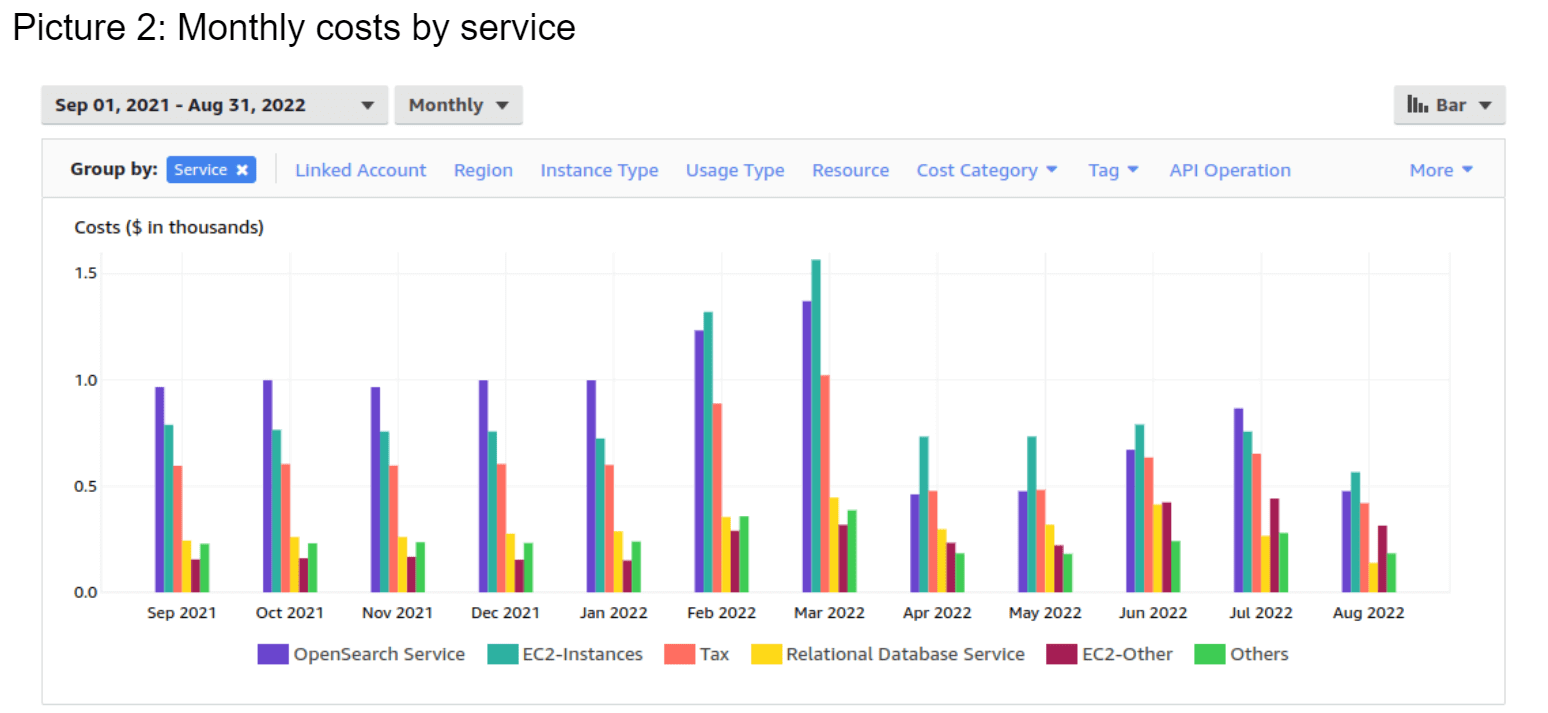
Monthly OpenSearch costs on the Choo project
#7 Remove unnecessary EBS snapshots
AWS supports both manual and automatic EBS snapshots – copies of your data at the point in time. You can store these snapshots in S3 buckets for disaster recovery or when migrating the data to other regions. The service supports both automated and manual snapshots. Over time, you’re likely to accumulate unused snapshots. Removing these idle snapshots can help you control cloud spending.
#8 Suspend unused Redshift (RS) clusters
Amazon Redshift clusters are an excellent option for cloud-based data warehousing. It uses a combination of storage and compute resources. RS clusters help companies analyze colossal amounts of data with the help of massively parallel processing (MPP). On-demand usage of RS clusters still forces you to pay for idle resources. A pause and resume option saves money when you don’t need to run your RS clusters.
#9 Remove unused Elastic IP addresses
AWS permits you to have no more than 5 Elastic IP addresses per region. This way, your application stays available during a failure by remapping its IPs to other instances without human intervention. However, when your app doesn’t actively use these Elastic IPs, AWS still bills you for them! So watch out for idle IP addresses to keep your costs down.
#10 Raise cost awareness across your teams
Many of the issues I’ve described above come from lack of awareness from the development team. In these cases, one of the DevOps engineers should explain to developers and stakeholders how their daily decisions affect the company’s cloud bills.
Conclusion
Cloud optimization is part science, part art, and a total necessity for any SaaS project. I hope these cloud cost optimization solutions help you to better understand your cloud spending. Uncovering the biggest money wasters on your company’s bill is the first step toward learning how to reduce cloud costs on a particular project.
Your next step might be implementing Infrastructure as Code, using Spot Instances, or reworking the architecture of your app. Whatever your current situation is, MindK is there to help you. We’ve been managing cloud costs for dozens of companies as a part of our DevOps services. Our experts can assess your infrastructure, create a personalized cost reduction roadmap, and help you implement it in a cost-effective fashion.
All you have to do is to drop us a line to get the ball rolling.





